
矩阵相关
低秩近似的方法:
-
插值分解(ID):https://kexue.fm/archives/10501
-
Monarch矩阵:https://kexue.fm/archives/10249
Lora:
- 梯度视角下的Lora:https://kexue.fm/archives/9590
- 学习率对Lora的影响:https://kexue.fm/archives/10001
- 核心结论:对于Lora AB,B的学习率 要大于A的学习率 :
- Lora改进1:https://kexue.fm/archives/10226
- 核心结论:对于Lora AB不必有一个矩阵初始化为全零,可以初始化为 \begin{equation}W = (W_0 - A_0 B_0) + AB\end{equation},即将原始减去AB初始的初始值,使用损失对 的初始梯度 进行SVD分解,,取U的前r列初始化A,取V的第r+1∼2r行初始化B。初始值的第一步更新接近原始全量微调的更新
- Lora改进2:https://kexue.fm/archives/10266
- 改进优化器或者说梯度计算方式,让AB的每一步更新尽可能接近全量微调的更新
- 有效秩:https://kexue.fm/archives/10847
SVD
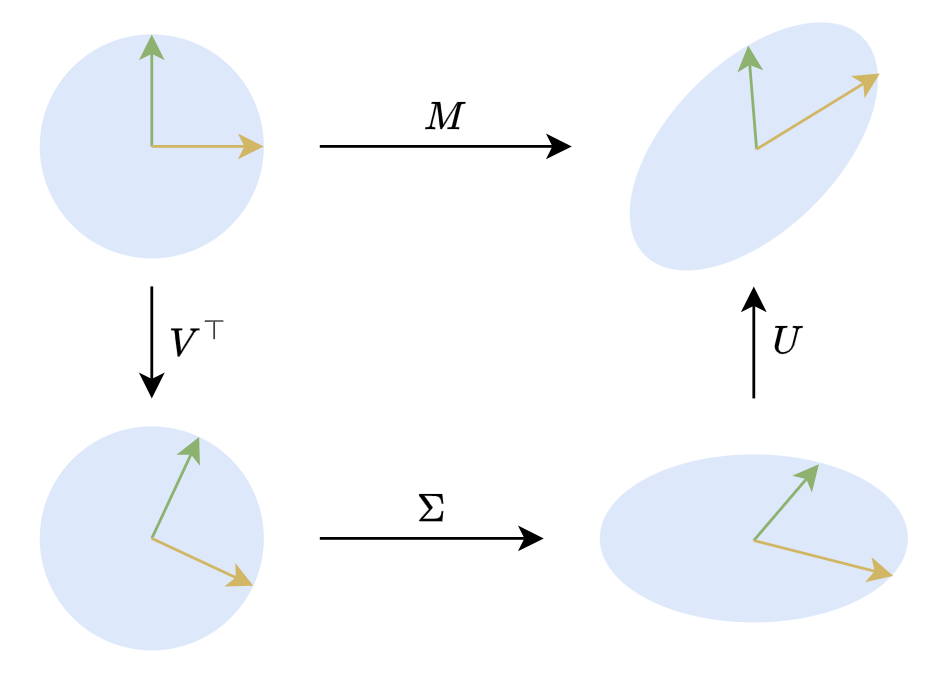
对于任意矩阵 ,都可以找到如下形式的奇异值分解(SVD,Singular Value Decomposition):
其中 都是正交矩阵, 是非负对角矩阵:
对角线元素默认从大到小排序,即 ,这些对角线元素就称为奇异值(Singular Value)。从数值计算角度看,我们可以只保留 中非零元素,将 的大小降低到 ( 是 的秩),保留完整的正交矩阵则更便于理论分析。
在二维平面下,实矩阵的SVD有非常直观的几何意义。二维的正交矩阵主要就是旋转(还有反射,但几何直观的话可以不那么严谨),所以 意味着任何对(列)向量x的线性变换,都可以分解为旋转、拉伸、旋转三个步骤,如下图所示:
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.