
YOLO系列论文解读(v1-v9)
[TOC]
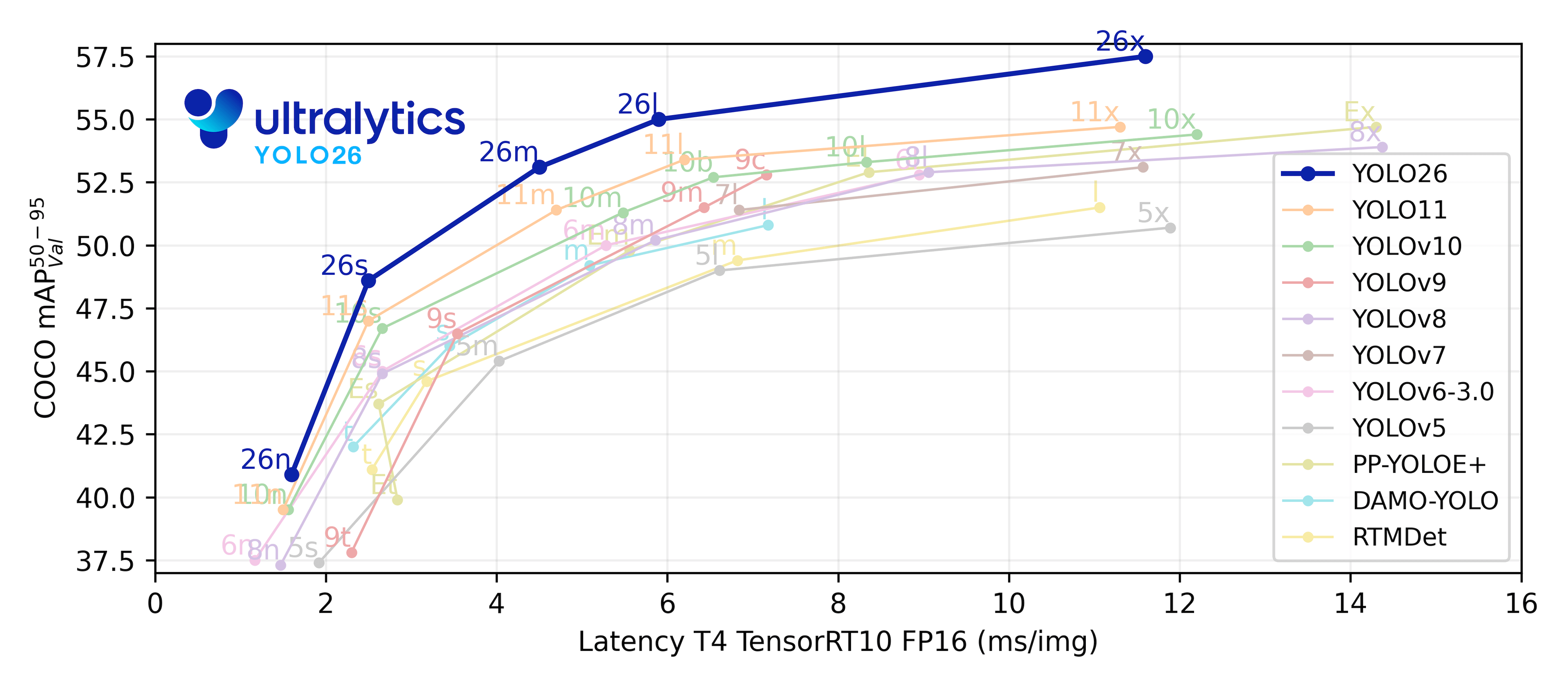
YOLO 简史
-
YOLO(You Only Look Once)是一种流行的目标检测和图像分割模型,于 2015 年推出,因其高速和高精度而广受欢迎。
-
YOLOv2于2016年发布,通过引入批量归一化(batch normalization)、锚框(anchor boxes)和维度聚类(dimension clusters),改进了原始模型。
-
YOLOv3于2018年推出,通过使用更高效的主干网络、多个锚点(multiple anchors)和空间金字塔池化(spatial pyramid pooling),进一步提高了模型的性能。
-
YOLOv4于 2020 年发布,引入了诸如 Mosaic 数据增强、一种新的无锚框检测头(anchor-free detection head)以及一种新的 损失函数等创新。
-
YOLOv5 进一步提高了模型的性能,并添加了新功能,例如超参数优化、集成实验跟踪和自动导出为流行的导出格式。
-
YOLOv7 添加了其他任务,例如在 COCO 关键点数据集上进行姿势估计。
-
YOLOv8 由Ultralytics 于 2023 年发布,引入了新功能和改进,以增强性能、灵活性和效率,并支持全方位的视觉 AI 任务。
-
YOLOv9 引入了诸如可编程梯度信息 (PGI) 和通用高效层聚合网络 (GELAN) 等创新方法。
-
YOLOv10 由清华大学的研究人员使用Ultralytics Python package创建,通过引入消除非极大值抑制 (NMS) 要求的端到端头部,提供实时的目标检测改进。
-
YOLO11:于 2024 年 9 月发布,YOLO11 在多项任务中表现出色,包括目标检测、分割、姿态估计、追踪和分类,可部署到各种 AI 应用和领域。
-
**YOLO26 **:Ultralytics 的下一代 YOLO 模型,针对边缘部署进行了优化,具有端到端无 NMS 推理功能。
YOLOv1(You Only Look Once)
- 官网:https://pjreddie.com/darknet/yolo/
- 论文:https://arxiv.org/abs/1506.02640
- 会议:CVPR 2016
1. 概述
YOLOv1(You Only Look Once version 1)是由 Joseph Redmon 等人在 2015 年提出的实时目标检测算法,首次发表于论文《You Only Look Once: Unified, Real-Time Object Detection》。与传统两阶段检测器(如 R-CNN 系列)不同,YOLOv1 将目标检测任务视为一个单阶段的回归问题,直接从图像像素预测边界框和类别概率,从而实现高速检测。
YOLOv1 的核心思想是:将输入图像划分为 S×S 的网格(grid cells),每个网格负责预测 B 个边界框(bounding boxes)及其置信度,以及 C 个类别概率。整个过程通过一个卷积神经网络端到端完成,仅需一次前向传播即可输出所有检测结果。
2. 网络结构
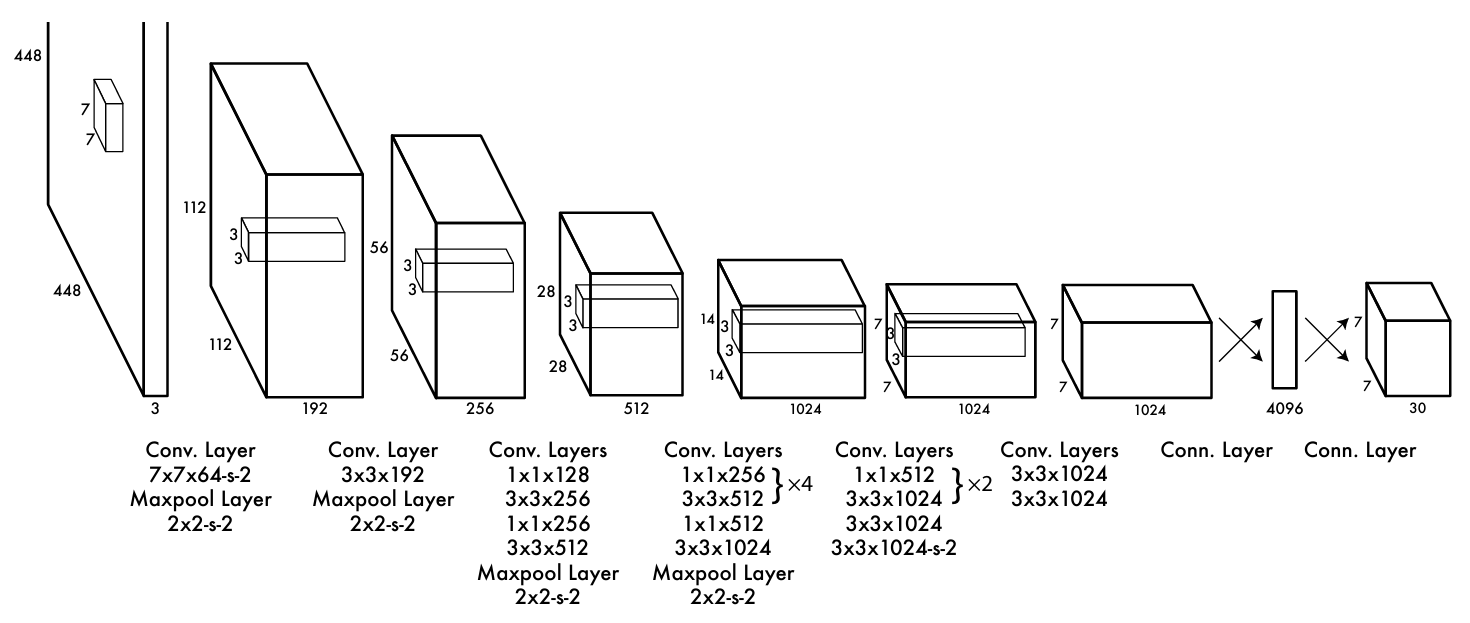
YOLOv1 使用一个定制的卷积神经网络作为骨干(backbone),其结构如下:
1 | import torch |
- 输入尺寸:448 × 448 × 3(RGB 图像)
- 卷积层:24 个卷积层,用于提取特征
- 前 20 层使用 3×3 和 1×1 卷积交替堆叠
- 后 4 层为高维特征提取层
- 全连接层:2 个全连接层(4096 → 7 × 7 × 30)
- 输出维度:S × S × (B × 5 + C)
- S是网格(特征图)尺寸,B是每个网格预测的bbox数,5是每个bbox需要预测的值,C是类别数
- 默认参数:S = 7, B = 2, C = 20(PASCAL VOC 数据集)
- 输出大小:7 × 7 × (2 × 5 + 20) = 7 × 7 × 30 = 1470
注:5 表示每个边界框包含 5 个值:(x, y, w, h, confidence)
3. 预测机制
3.1 网格划分
- 输入图像被划分为 S×S(默认 7×7)的网格。
- 若某个物体的中心落在某个网格内,则该网格负责预测该物体。
3.2 边界框预测
- 每个网格预测 B(默认为 2)个边界框。
- 每个边界框包含:
- 中心坐标 (x, y):相对于当前网格左上角的偏移(归一化到 [0,1])
- 宽高 (w, h):相对于整张图像的宽高(归一化)
- 置信度(confidence):
- 若无物体,置信度为 0
- 若有物体,置信度为预测框与真实框的 IoU
3.3 类别预测
- 每个网格预测一组类别概率 ,共 C 个(C=20 for VOC)
- 注意:类别概率是每个网格一份,而非每个边界框一份
3.4 最终检测结果
-
对每个边界框计算类别置信度:
-
使用非极大值抑制(NMS)去除冗余检测框
4. 损失函数
YOLOv1 使用多任务损失函数,统一回归边界框、置信度和类别概率:
边界框损失(中心坐标和宽高):
置信度损失:
类别概率损失:
其中:
- :第 i 个网格的第 j 个边界框是否负责预测某个真实物体(即该物体中心落在该网格中)
- :没有包含物体的网格(即物体中心没有落到的网格中)
- :加大定位误差权重
- :降低无物体时的置信度误差权重
- 对 w、h 使用平方根是为了对小框的误差给予更高惩罚
5. 优缺点分析
优点:
- 速度快:单次前向传播,可实现实时检测(VOC 上达 45 FPS)
- 全局推理:直接在整图上进行预测,减少背景误检
- 端到端训练:无需复杂的流水线(如候选区域生成)
缺点:
- 定位精度较低:尤其对小物体和密集物体表现不佳
- 每个网格最多预测 B 个物体:难以处理同一网格内多个物体的情况
- 泛化能力有限:对新奇长宽比或分布外物体鲁棒性差
6. 实验与性能(PASCAL VOC 2007)
| 方法 | mAP (%) | 推理速度 (FPS) |
|---|---|---|
| R-CNN | 58.5 | ~0.03 |
| Fast R-CNN | 68.4 | ~0.5 |
| Faster R-CNN | 73.2 | ~5–7 |
| YOLOv1 | 63.4 | 45 |
虽然 mAP 低于两阶段方法,但速度优势显著。
7. 总结
YOLOv1 开创了单阶段目标检测的先河,其“将检测视为回归问题”的思想影响深远。尽管存在定位不准、漏检等问题,但它为后续 YOLOv2/v3/v4/v5/v8 等高效检测器奠定了基础。YOLO 系列至今仍是工业界最广泛使用的实时目标检测框架之一。
YOLOv2(You Only Look Once v2)
1. 概述
YOLOv2(又称 YOLO9000)由 Joseph Redmon 和 Ali Farhadi 于 2016 年提出,发表在论文《YOLO9000: Better, Faster, Stronger》中。YOLOv2 在 YOLOv1 的基础上进行了多项关键改进,显著提升了检测精度和速度,同时引入了联合训练策略,使其能够检测超过 9000 种物体类别。
YOLOv2 的设计目标是:在保持实时性的同时,提高检测准确率,并扩展到更大规模的类别集合。它通过引入一系列工程与算法优化,在 PASCAL VOC 和 COCO 等基准上实现了优于 Faster R-CNN 的性能,同时推理速度更快。
2. 核心改进
YOLOv2 相比 YOLOv1 引入了以下关键技术:
| 改进项 | 说明 |
|---|---|
| Batch Normalization | 所有卷积层后添加 BN 层,提升收敛速度和模型稳定性,mAP 提升约 2% |
| 高分辨率分类器微调 | 先在 ImageNet 上以 448×448 分辨率微调分类网络,缓解检测与分类输入尺寸不一致问题 |
| 使用 Anchor Boxes | 借鉴 Faster R-CNN,用先验框(anchors)替代 YOLOv1 的直接回归,提升召回率 |
| Dimension Clusters | 使用 k-means 聚类在训练集边界框上自动学习 anchor 尺寸,避免人工设定 |
| Location Prediction with Constraints | 对 anchor 的偏移量预测施加约束,确保训练稳定 |
| Passthrough Layer | 引入细粒度特征融合机制,将浅层高分辨率特征传递到深层,提升小物体检测能力 |
| Multi-Scale Training | 训练时动态调整输入图像尺寸(320–608),增强模型对不同尺度的鲁棒性 |
| High-Resolution Detector | 最终输入尺寸为 416×416(非 448),使特征图尺寸为奇数(13×13),便于定位中心 |
3. 网络结构:Darknet-19
YOLOv2 采用全新的骨干网络 Darknet-19,其特点如下:
-
输入尺寸:可变(训练时多尺度,测试常用 416×416)
-
卷积层数:19 层(含 16 个 conv + 5 个 maxpool + 1 个 global avg pool)
-
使用大量 3×3 和 1×1 卷积交替堆叠
-
每个卷积层后接 Batch Normalization 和 Leaky ReLU
-
最终使用全局平均池化代替全连接层,减少参数量
-
在 ImageNet 上 top-1 准确率达 72.9%,速度快且轻量
输出层:对于 PASCAL VOC(20 类),输出为 13×13×(5×(5+20)) = 13×13×125 > 其中 5 是 anchor 数量,5 表示 (x, y, w, h, confidence)
4. Anchor Boxes 与边界框预测
4.1 Anchor 设计
- 使用 k-means(k=5)在 COCO 数据集上聚类边界框尺寸,得到 5 个先验框(anchors)
- 距离度量采用 IoU 而非欧氏距离:
4.2 边界框预测方式
每个 grid cell 预测相对于 anchor 的偏移量:
- $ t_x, t_y $ :中心偏移(经 sigmoid 限制在 [0,1] 内)
- $t_w, t_h $ :宽高缩放(无约束,通过指数变换)
最终预测公式:
其中 是 grid cell 左上角坐标, 是 anchor 尺寸。
此设计使梯度更稳定,避免预测框任意漂移。
5. 多尺度训练(Multi-Scale Training)
- 网络输入尺寸必须是 32 的倍数(因下采样 32 倍)
- 每隔 10 个 batch 随机选择一个新尺寸(如 320, 352, …, 608)
- 使同一网络能适应不同分辨率输入
- 测试时可灵活选择速度/精度平衡点:
- 低分辨率(如 320×320):>90 FPS,适合嵌入式设备
- 高分辨率(如 608×608):精度更高,接近 SOTA
6. YOLO9000:联合训练检测与分类
YOLOv2 的扩展版本 YOLO9000 实现了检测 9000+ 类物体的能力,其核心是联合训练策略:
-
数据来源:
- 检测数据:带边界框标注(如 COCO)
- 分类数据:仅图像标签(如 ImageNet)
-
层级标签体系:
- 构建 WordTree(词树),将 ImageNet 与 COCO 类别统一到语义层次结构中
- 例如:“狗” → “金毛”、“哈士奇”等子类
-
训练机制:
- 若样本来自检测数据集,则正常更新定位和分类损失
- 若来自分类数据集,则只更新分类分支,并沿 WordTree 向上传播概率
这使得模型能对未见过的类别进行合理推理(如检测“诺福克梗”即使训练集中无该类检测样本)
7. 损失函数
YOLOv2 的损失函数继承自 YOLOv1,但适配了 anchor 机制:
- 定位损失:仅对负责预测物体的 anchor 计算(IoU 最大的那个)
- 置信度损失:区分 obj / noobj(仍使用 λ_noobj = 0.5)
- 分类损失:仅当网格包含物体时计算
- 不再使用平方根处理 w/h,因 anchor 已提供合理初始值
8. 性能对比(PASCAL VOC 2007)
| 方法 | mAP (%) | 推理速度 (FPS) | 输入尺寸 |
|---|---|---|---|
| YOLOv1 | 63.4 | 45 | 448×448 |
| Faster R-CNN | 73.2 | 7 | ~600×~1000 |
| YOLOv2 | 78.6 | ≥67 | 416×416 |
YOLOv2 在速度和精度上均超越 YOLOv1 和 Faster R-CNN。
在 COCO 上,YOLOv2 达到 44.0 [email protected],速度达 40–60 FPS。
9. 优缺点分析
优点:
- 精度显著提升(+5.2 mAP on VOC)
- 保持实时性(>60 FPS)
- 支持多尺度输入,部署灵活
- YOLO9000 实现大规模类别检测
- 使用 anchor + 聚类,提升召回率
缺点:
- 对密集小物体仍存在漏检
- 每个 grid cell 仍只能分配一个 ground truth(尽管有多个 anchors)
- WordTree 依赖语义层级,对非层级类别泛化有限
10. 总结
YOLOv2 是 YOLO 系列的重要里程碑,通过引入 anchor boxes、BatchNorm、多尺度训练、细粒度特征融合等技术,大幅提升了检测性能。其提出的 Darknet-19 成为后续轻量级检测器的参考架构,而 YOLO9000 的联合训练思想也为弱监督和开放词汇检测提供了新思路。
YOLOv3(You Only Look Once v3)
1. 概述
YOLOv3 由 Joseph Redmon 和 Ali Farhadi 于 2018 年提出,发表在技术报告《YOLOv3: An Incremental Improvement》中。作为 YOLO 系列的第三代模型,YOLOv3 在保持实时推理速度的同时,显著提升了对小物体和多尺度目标的检测能力,并增强了对遮挡、密集场景的鲁棒性。
YOLOv3 并未引入颠覆性创新,而是融合了当时计算机视觉领域的多项成熟技术(如残差网络、FPN、多尺度预测等),通过工程优化实现了精度与速度的良好平衡。它成为工业界最广泛部署的目标检测模型之一,尤其适用于嵌入式设备和实时视频分析场景。
2. 核心改进
相比 YOLOv2,YOLOv3 的主要改进包括:
| 改进项 | 说明 |
|---|---|
| Darknet-53 骨干网络 | 引入残差结构(借鉴 ResNet),提升特征提取能力 |
| 多尺度预测(FPN-like) | 在三个不同尺度上进行检测,增强小物体召回率 |
| 独立的类别预测(Logistic + BCE) | 使用二元交叉熵代替 softmax,支持多标签分类 |
| 更精细的 anchor 设计 | 基于 k-means 聚类得到 9 个 anchors,分配到 3 个尺度 |
| 无全连接层 | 完全卷积化,支持任意尺寸输入 |
3. 网络结构:Darknet-53
YOLOv3 采用 Darknet-53 作为主干特征提取网络:
- 输入尺寸:通常为 416×416(也可为 320、608 等)
- 结构特点:
- 包含 53 个卷积层(不含池化)
- 大量使用 残差块(Residual Block):每个 block 包含两个 3×3 卷积,跳过连接缓解梯度消失
- 下采样通过 stride=2 的卷积实现(无 max pooling)
- 性能对比:
- ImageNet 分类 top-1 准确率:77.2%
- 推理速度比 ResNet-101 快 1.5 倍,精度更高
Darknet-53 在精度与速度之间取得良好平衡,成为 YOLOv3 高性能的基础。
4. 多尺度预测机制
YOLOv3 借鉴 Feature Pyramid Network(FPN)思想,在三个不同尺度上进行检测:
| 输出层 | 特征图尺寸 | 对应感受野 | 擅长检测 |
|---|---|---|---|
| Large-scale | 13×13 | 大 | 大物体 |
| Medium-scale | 26×26 | 中 | 中等物体 |
| Small-scale | 52×52 | 小 | 小物体 |
特征融合方式:
- 从深层(13×13)开始预测
- 上采样深层特征 → 与中间层(26×26)拼接 → 预测中尺度
- 再上采样 → 与浅层(52×52)拼接 → 预测小尺度
这种“自顶向下 + 横向连接”结构显著提升了小目标检测性能。
5. Anchor Boxes 与输出设计
- 使用 k-means 聚类在 COCO 数据集上聚出 9 个 anchors
- 将 9 个 anchors 按面积大小均分为三组,分别用于三个尺度:
- 13×13 层:(116×90), (156×198), (373×326)
- 26×26 层:(30×61), (62×45), (59×119)
- 52×52 层:(10×13), (16×30), (33×23)
每个尺度的输出张量维度为:
其中:
- 3:该尺度使用的 anchor 数量
- 5:(x, y, w, h, objectness confidence)
- C:类别数(COCO 为 80)
6. 类别预测:多标签分类
YOLOv3 放弃 softmax,改用 独立的 logistic 分类器 + 二元交叉熵(BCE)损失:
- 每个类别独立预测概率 ( p \in [0,1] )
- 允许一个物体属于多个类别(如 “woman” 和 “person”)
- 更适合处理标签不互斥的场景(如 Open Images)
此设计提高了模型在复杂数据集上的灵活性和泛化能力。
7. 损失函数
YOLOv3 的损失函数包含三部分:
-
定位损失(L2)
- 对负责预测的 anchor 计算 (x, y, w, h) 的平方误差
- (w/h 仍使用原始值,未开根号)
-
置信度损失(BCE)
- 有物体:预测 IoU 与真实 IoU 的 BCE
- 无物体:仅计算负样本置信度(使用 λ_noobj ≈ 1)
-
分类损失(BCE)
对每个类别独立计算二元交叉熵
注意:YOLOv3 不再使用 YOLOv1 中的 λ_coord 权重,因 anchor 提供了良好初始化。
8. 性能表现(COCO test-dev)
| 模型 | [email protected] | mAP@[0.5:0.95] | 推理速度(Titan X) |
|---|---|---|---|
| YOLOv2 | 69.0 | 21.6 | ~67 FPS |
| SSD512 | 68.3 | 28.8 | ~19 FPS |
| Faster R-CNN | 76.4 | 34.9 | ~7 FPS |
| YOLOv3-416 | 57.9 | 33.0 | ≥60 FPS |
| YOLOv3-608 | 61.2 | 36.5 | ~45 FPS |
虽然 [email protected] 低于 YOLOv2(因 COCO 评价标准更严),但 mAP@[0.5:0.95] 显著提升,说明定位更精准。
在 PASCAL VOC 上,YOLOv3 达到 82.0 mAP,超越 YOLOv2。
9. 优缺点分析
优点:
- 多尺度检测显著提升小物体性能
- Darknet-53 + 残差结构特征表达能力强
- 完全卷积,支持任意输入尺寸
- 多标签分类更符合现实场景
- 速度快、精度高,适合工业部署
缺点:
- 对极小或严重遮挡物体仍有漏检
- 模型较大(约 236 MB),对边缘设备仍有压力
- 未使用注意力机制或更先进训练策略(如 label smoothing)
10. 总结
YOLOv3 是 YOLO 系列中最稳定、最实用的版本之一。它通过融合残差网络、FPN 多尺度预测、逻辑分类器等成熟技术,在不牺牲速度的前提下大幅提升了检测精度,尤其在小目标和复杂场景中表现优异。
尽管后续出现了 YOLOv4、v5、v8 等改进版本,YOLOv3 因其简洁性、可复现性和良好性能,至今仍在大量实际项目中被广泛使用。
YOLOv4(You Only Look Once v4)
1. 概述
YOLOv4 由 Alexey Bochkovskiy、Chien-Yao Wang 和 Hong-Yuan Mark Liao 于 2020 年提出,发表在论文《YOLOv4: Optimal Speed and Accuracy of Object Detection》中。与前几代由 Joseph Redmon 主导不同,YOLOv4 是社区驱动的工程集大成之作,系统性地验证并整合了近年来目标检测领域的大量有效技巧(Bag of Freebies / Bag of Specials),在保持实时推理速度的同时,显著提升了精度。
YOLOv4 的核心理念是:在常规 GPU(如 GTX 1080Ti 或 RTX 2080)上实现最优的速度-精度平衡,无需专用硬件或复杂训练策略,即可达到 SOTA(State-of-the-Art)水平。
2. 核心贡献
YOLOv4 并未提出全新网络结构,而是通过以下方式实现性能突破:
2.1 系统性实验验证
- 提出 “Bag of Freebies”(不增加推理成本的训练技巧):
- 数据增强:Mosaic、CutMix、Class Label Smoothing、DropBlock
- 损失函数改进:CIoU Loss、CIOU-based NMS
- 提出 “Bag of Specials”(轻微增加推理成本但显著提升精度的模块):
- PANet + SPP 结构
- Mish 激活函数
- Cross mini-Batch Normalization(CmBN)
- Self-Adversarial Training(SAT)
2.2 高效骨干网络:CSPDarknet53
- 基于 Darknet53 引入 Cross Stage Partial Network(CSPNet)
- 减少重复梯度信息,提升计算效率和精度
- 在 ImageNet 上优于 ResNet-101,且推理更快
2.3 改进的检测头:PANet + SPP
- SPP(Spatial Pyramid Pooling)模块:融合多尺度上下文信息,增强感受野
- PANet(Path Aggregation Network):自底向上 + 自顶向下路径融合,强化特征金字塔
3. 网络架构
YOLOv4 整体结构分为三部分:
| 组件 | 说明 |
|---|---|
| Backbone | CSPDarknet53(含 Mish 激活、CmBN) |
| Neck | SPP + PANet(特征融合) |
| Head | YOLOv3-style 多尺度检测头(3 个输出层) |
输入与输出
- 默认输入尺寸:608×608(可调)
- 输出尺度:76×76(小物体)、38×38(中)、19×19(大)
- 每个尺度预测 3 个 anchor boxes(共 9 个,由 k-means 聚类获得)
4. 关键技术详解
4.1 CSPDarknet53
- 将输入通道分为两部分:一部分直接 bypass,另一部分进入残差块
- 减少计算量约 20%,同时提升准确率
- 使用 Mish 激活函数($ x \cdot \tanh(\ln(1 + e^x)) $),比 Leaky ReLU 更平滑,梯度更稳定
4.2 SPP 模块
- 在 backbone 末端插入 SPP 层(含 5×5, 9×9, 13×13 最大池化)
- 固定输出尺寸,增强对不同尺度目标的鲁棒性
- 不增加推理延迟(因并行池化)
4.3 PANet 特征融合
- 在 FPN(自顶向下)基础上增加 自底向上路径
- 低层语义信息可直达高层,高层语义也可反馈至底层
- 显著提升小目标和定位精度
4.4 Mosaic 数据增强
- 每次训练随机拼接 4 张图像为一张
- 增强模型对小目标、多目标、跨域场景的泛化能力
- 减少对 Batch Normalization 的依赖
4.5 CIoU Loss
- 改进 IoU Loss,引入:
- 重叠面积(IoU)
- 中心点距离
- 宽高比一致性
- 加速收敛,提升边界框回归精度
4.6 Self-Adversarial Training(SAT)
- 第一阶段:正常训练
- 第二阶段:固定网络,对输入图像进行对抗扰动,使网络“自我欺骗”
- 提升模型鲁棒性,尤其对遮挡和噪声
5. 训练策略
- 优化器:SGD with momentum(初始 lr=0.0013,余弦退火)
- Batch Size:64(使用 multi-scale training 可适应不同 GPU)
- Multi-Scale Training:每 10 个 batch 随机调整输入尺寸(320–608)
- 正则化:DropBlock(比 Dropout 更适合卷积网络)
6. 性能表现(COCO test-dev)
| 模型 | [email protected] | mAP@[0.5:0.95] | 推理速度(RTX 2080Ti) |
|---|---|---|---|
| YOLOv3-608 | 57.9 | 33.0 | ~45 FPS |
| EfficientDet-D3 | 57.8 | 42.6 | ~10 FPS |
| YOLOv4-608 | 65.7 | 43.5 | ≥62 FPS |
| YOLOv4-tiny | 41.2 | 22.0 | >200 FPS |
YOLOv4 在 COCO 上首次实现 >65 [email protected] 且 >60 FPS,成为当时最快的高精度检测器。
7. 优缺点分析
优点:
- 精度与速度兼得:在单张消费级 GPU 上达到 SOTA
- 工程友好:无需特殊硬件,训练/部署简单
- 模块化设计:各组件可独立替换(如换 backbone)
- 开源完善:官方提供 Darknet 实现,社区支持丰富
缺点:
- 模型较大(约 245 MB),对嵌入式设备不友好
- 训练资源需求高(建议 16GB+ GPU 显存)
- 部分技巧(如 SAT)增加训练复杂度
8. YOLOv4 变体
- YOLOv4-tiny:轻量化版本,适用于边缘设备(Jetson Nano、树莓派)
- YOLOv4-CSP:进一步优化 CSP 结构
- Scaled-YOLOv4(后续工作):基于 YOLOv4 的缩放策略,衍生出 YOLOv4-large 等
9. 总结
YOLOv4 是目标检测领域的一座工程丰碑。它通过严谨的实验验证,将数十种前沿技术有机整合,在不牺牲实时性的前提下,将 YOLO 系列的精度推向新高度。其“实用主义”设计理念——在普通硬件上实现最优性能——使其成为工业界最受欢迎的检测框架之一。
尽管后续出现了 YOLOv5(Ultralytics)、YOLOv6/v7/v8(美团、Alexey 等),YOLOv4 仍因其稳定性、可解释性和高性能,被广泛应用于安防、自动驾驶、工业质检等领域。
YOLOv5(You Only Look Once v5)
1. 概述
YOLOv5 由 Ultralytics 团队于 2020 年 6 月首次开源发布,是 YOLO 系列中首个非官方但广泛流行的版本。尽管其命名延续了 YOLO 序列,但 YOLOv5 并未发表于学术会议或期刊,而是以工程实现和易用性为核心目标。
YOLOv5 的核心优势在于:PyTorch 原生实现、模块化设计、训练/部署一体化、支持多平台导出(ONNX、TensorRT、CoreML 等),使其迅速成为工业界最常用的目标检测框架之一。它在保持与 YOLOv4 相当精度的同时,显著简化了使用流程,并提供了灵活的模型缩放策略。
注意:YOLOv5 并非 Joseph Redmon 或 Alexey Bochkovskiy 官方作品,而是社区驱动的高质量实现。
2. 核心特点
| 特性 | 说明 |
|---|---|
| PyTorch 原生 | 使用 PyTorch 编写,支持自动混合精度(AMP)、分布式训练、可视化调试 |
| 模型缩放系列 | 提供 YOLOv5n/s/m/l/x 五种尺寸,满足不同算力需求 |
| AutoAnchor | 自动根据数据集边界框分布优化 anchor 尺寸 |
| Mosaic + MixUp | 默认启用高级数据增强,提升小目标和泛化能力 |
| Focus 结构(早期版本) | 切片拼接下采样,减少计算量(v6.0 后被替换为标准卷积) |
| 解耦头(Decoupled Head) | 分离分类与回归分支,提升收敛速度(v6.0+ 引入) |
| CIoU / DIoU Loss | 改进边界框回归损失,提升定位精度 |
| 一键部署 | 支持导出为 ONNX、TensorRT、OpenVINO、CoreML、TFLite 等格式 |
3. 网络架构
YOLOv5 整体采用 “Backbone + Neck + Head” 三段式结构:
3.1 Backbone:增强 CSPNet
- 基于 CSPDarknet 改进(受 YOLOv4 启发)
- 使用 SiLU(Swish)激活函数(替代 Leaky ReLU/Mish)
- 包含多个 C3 模块(Cross Stage Partial + 3 个卷积层)
- 下采样通过 stride=2 卷积实现
3.2 Neck:PAN-FPN
- 融合 FPN(自顶向下) + PAN(自底向上)
- 多尺度特征交互,强化小目标检测能力
- 使用 上采样 + 拼接(concat) 而非相加(add)
3.3 Head:Anchor-Based 检测头
- 三个输出尺度(如 80×80, 40×40, 20×20 for 640×640 input)
- 每个尺度预测 3 个 anchor boxes(共 9 个)
- 输出内容:(x, y, w, h, objectness, class_probs)
从 YOLOv5 v6.0 开始,引入 解耦检测头(Decoupled Head),将分类与回归路径分离,进一步提升精度。
4. 模型系列(Scale Variants)
YOLOv5 提供五种预定义模型,通过深度(depth_multiple)和宽度(width_multiple)控制:
| 模型 | 参数量 | FLOPs (640×640) | COCO [email protected] | 速度(V100) |
|---|---|---|---|---|
| YOLOv5n(nano) | 1.9M | 4.5B | 28.0 | ~140 FPS |
| YOLOv5s(small) | 7.2M | 16.5B | 37.4 | ~90 FPS |
| YOLOv5m(medium) | 21.2M | 49.0B | 45.4 | ~50 FPS |
| YOLOv5l(large) | 46.5M | 109.1B | 49.0 | ~30 FPS |
| YOLOv5x(extra) | 86.7M | 205.7B | 50.7 | ~20 FPS |
所有模型均在 COCO train2017 上训练,输入尺寸为 640×640。
5. 训练与推理优化
5.1 数据增强
- Mosaic:4 图拼接(默认开启)
- MixUp:图像线性混合(后期 epoch 启用)
- HSV 调整、随机翻转、仿射变换等
5.2 自动超参调优
hyperparameter evolution:基于遗传算法自动搜索最优 lr、momentum、augment ratio 等
5.3 自动 Anchor 优化
k-means在训练集上聚类边界框- 若 IoU 提升 > 阈值,则替换默认 anchors
5.4 推理加速
- 支持 TensorRT(GPU)、OpenVINO(Intel CPU)、CoreML(Apple)
- 可导出为 ONNX 通用格式,便于跨平台部署
6. 性能对比(COCO val2017)
| 模型 | [email protected] | mAP@[0.5:0.95] | 参数量 | 推理速度(ms, V100) |
|---|---|---|---|---|
| YOLOv4 | 65.7 | 43.5 | ~62M | ~16 ms |
| YOLOv5s | 56.8 | 37.4 | 7.2M | ~3.5 ms |
| YOLOv5m | 63.3 | 44.2 | 21.2M | ~6.5 ms |
| YOLOv5l | 66.0 | 47.2 | 46.5M | ~10 ms |
| EfficientDet-D1 | 56.1 | 39.6 | 6.6M | ~25 ms |
YOLOv5l 在精度上超越 YOLOv4,且推理更快;YOLOv5s 在轻量级场景极具竞争力。
7. 优缺点分析
优点:
- 开箱即用:提供完整训练/验证/推理/部署 pipeline
- PyTorch 生态友好:易于调试、修改、集成
- 多平台部署支持:覆盖移动端、嵌入式、服务器
- 活跃社区:GitHub 超 30k stars,持续更新
- 灵活缩放:从 nano 到 extra,适配各种硬件
缺点:
- 非学术论文发布:缺乏理论创新性证明
- 早期 Focus 层争议:被质疑为“伪创新”(后已弃用)
- 默认配置偏向速度:高精度需手动调参或使用大模型
9. 总结
YOLOv5 并非传统意义上的“学术突破”,而是一次工程卓越性的典范。它将目标检测的复杂流程封装为简洁、高效、可扩展的工具链,极大降低了 AI 落地门槛。凭借其易用性、灵活性和高性能,YOLOv5 成为工业界事实上的标准检测框架之一。
尽管后续出现了 YOLOv6(美团)、YOLOv7(Alexey)、YOLOv8(Ultralytics 新一代),YOLOv5 因其成熟稳定,仍在大量生产环境中被广泛使用。
YOLOv6(You Only Look Once v6)
1. 概述
YOLOv6 由 美团视觉智能部 于 2022 年 6 月开源发布,论文《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》系统性地针对工业部署场景进行了优化。与 YOLOv5 强调易用性不同,YOLOv6 聚焦于 “硬件友好”、“高精度”与“低延迟” 的统一,特别适用于边缘设备(如 NVIDIA Jetson、ARM CPU)和大规模视频分析系统。
YOLOv6 的核心理念是:在不牺牲推理速度的前提下,通过结构重参数化、高效骨干网络和自蒸馏等技术,提升模型精度与部署效率。其设计充分考虑了现代 AI 芯片的计算特性(如 GPU 的 Tensor Core、NPU 的 INT8 优化),成为面向工业落地的新一代 YOLO 变体。
2. 核心创新
| 技术 | 说明 |
|---|---|
| RepVGG-style Backbone | 使用结构重参数化(Reparameterization)构建高效骨干网络 |
| Anchor-Free 检测头 | 放弃 anchor boxes,简化预测逻辑,降低后处理开销 |
| SimOTA 动态标签分配 | 更优的正负样本匹配策略,提升训练稳定性 |
| Self-Distillation 自蒸馏 | 利用教师模型(EMA)指导学生训练,提升小模型精度 |
| 硬件感知设计 | 网络结构适配 GPU/NPU 计算单元,减少内存访问瓶颈 |
3. 网络架构
YOLOv6 采用 “Backbone + Neck + Head” 三段式设计,但与 YOLOv5/v4 有显著差异:
3.1 Backbone:EfficientRep / CSPBep
- 基于 RepVGG 思想,使用 RepBlock(训练时多分支,推理时融合为单 3×3 卷积)
- 在训练阶段包含 identity + 1×1 + 3×3 分支,推理时等效合并,无额外推理成本
- 后续版本(v3.0+)引入 CSPBep 结构,结合 Cross Stage Partial 与 BepBlock,进一步提升效率
3.2 Neck:Rep-PAN
- 改进的 PANet,同样采用重参数化卷积
- 特征融合路径优化,减少通道数冗余
- 支持多尺度特征交互(P3/P4/P5)
3.3 Head:Anchor-Free
- 不再使用 anchor boxes
- 每个 grid cell 直接预测:
- 中心点偏移 (tx, ty)
- 宽高 (tw, th)(以 stride 为单位)
- 分类分数(多标签 BCE)
- objectness(部分版本保留)
- 输出维度:H × W × (4 + C)
Anchor-Free 设计简化了超参(无需聚类 anchors),并减少 NMS 后处理负担。
4. 关键技术详解
4.1 结构重参数化(Reparameterization)
- 训练时:使用多分支结构(如 3×3 conv + 1×1 conv + identity)增强表达能力
- 推理时:将多分支等效融合为单个 3×3 卷积,零额外延迟
- 优势:训练更强,推理更快,适合部署
4.2 SimOTA 标签分配
- 动态选择正样本:基于预测框与 GT 的 cost(IoU + 分类 loss)
- 解决传统静态分配(如 YOLOv3 的中心点规则)导致的样本不平衡问题
- 提升小目标和密集场景的召回率
4.3 自蒸馏(Self-Distillation)
- 使用 EMA(指数移动平均)模型作为教师
- 对分类和回归输出施加 KL 散度或 L2 损失
- 尤其提升 YOLOv6-Nano/Tiny 等小模型的精度(+1~2 mAP)
4.4 硬件感知优化
- 避免使用 depthwise convolution(在 GPU 上效率低)
- 减少特征图通道跳跃(如 96 → 128 → 256 而非 96 → 256)
- 对齐 Tensor Core 的 8/16 通道对齐要求
5. 模型系列
YOLOv6 提供多个尺寸版本,适配不同算力平台:
| 模型 | 输入尺寸 | 参数量 | FLOPs | COCO [email protected] | 推理速度(Tesla T4) |
|---|---|---|---|---|---|
| YOLOv6-N(Nano) | 416 | 4.0M | 4.7G | 31.2 | ~1.3 ms |
| YOLOv6-T(Tiny) | 640 | 15.0M | 36.7G | 41.3 | ~2.5 ms |
| YOLOv6-S(Small) | 640 | 34.3M | 85.8G | 43.6 | ~3.8 ms |
| YOLOv6-M(Medium) | 640 | 59.4M | 150.7G | 49.0 | ~6.2 ms |
| YOLOv6-L(Large) | 640 | 77.1M | 214.0G | 51.8 | ~8.5 ms |
所有模型均在 COCO train2017 上训练,测试使用 val2017。
6. 性能对比(COCO val2017)
| 模型 | [email protected] | mAP@[0.5:0.95] | 推理速度(T4, ms) | 备注 |
|---|---|---|---|---|
| YOLOv5s | 56.8 | 37.4 | ~2.8 | Anchor-based |
| YOLOv6-T | 59.5 | 41.3 | ~2.5 | Anchor-free |
| YOLOv6-S | 63.3 | 44.5 | ~3.8 | — |
| PP-YOLOE-S | 61.2 | 43.0 | ~4.0 | PaddlePaddle |
| EfficientDet-D2 | 60.0 | 42.0 | ~15 | — |
YOLOv6 在相同 FLOPs 下,精度显著优于 YOLOv5,且推理更快。
7. 优缺点分析
优点:
- Anchor-Free 简化流程:无需 anchor 聚类,部署更轻量
- 重参数化提升效率:训练强,推理快,无额外开销
- 工业级优化:专为 GPU/NPU 部署设计,延迟低
- 开源完善:提供 PyTorch 训练 + TensorRT/C++ 推理 SDK
- 自蒸馏有效:小模型精度提升明显
缺点:
- 早期版本不支持多尺度训练(v3.0+ 已加入)
- 对极小目标检测仍弱于 FPN-heavy 模型
- 社区生态略逊于 YOLOv5
9. 总结
YOLOv6 是 YOLO 系列中首个由工业界主导、深度面向部署优化的版本。它通过结构重参数化、Anchor-Free 设计、自蒸馏和硬件感知架构,在精度与速度之间取得了新的平衡。尤其在边缘计算和视频监控场景中,YOLOv6 展现出强大的实用价值。
尽管 YOLOv8 等后续版本进一步演进,YOLOv6 凭借其高效的 Rep-based 结构和工业级工程实现,仍是高吞吐、低延迟检测任务的重要选择。
YOLOv7(You Only Look Once v7)
1. 概述
YOLOv7 由 Alexey Bochkovskiy 团队(YOLOv4 作者)与 Chien-Yao Wang(YOLOv4 共同作者)于 2022 年 7 月提出,发表在论文《YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors》中。作为 YOLO 系列的又一里程碑,YOLOv7 在不增加推理成本的前提下,通过可训练的“免费赠品”(Trainable Bag-of-Freebies)技术,刷新了实时目标检测的精度记录。
YOLOv7 的核心思想是:优化训练过程本身,使模型在相同架构下学到更优表示。它在 COCO 数据集上以 56.8% mAP@[0.5:0.95] 的成绩超越所有已知实时检测器(包括 YOLOv5、YOLOv6、Scaled-YOLOv4),同时保持 30+ FPS 的推理速度(V100 GPU)。
2. 核心创新
| 技术 | 说明 |
|---|---|
| Extended Efficient Layer Aggregation Networks (E-ELAN) | 改进特征聚合方式,提升梯度流效率 |
| Model Scaling for Concatenation-based Models | 提出适用于拼接型网络的缩放策略 |
| Trainable Bag-of-Freebies (BoF) | 引入可学习的数据增强与标签分配机制 |
| Coarse-to-Fine Dynamic Label Assignment | 动态、多尺度正负样本分配策略 |
| Auxiliary Head with Implicit Knowledge | 辅助检测头引入隐式表示,提升主干学习能力 |
3. 网络架构
YOLOv7 延续 “Backbone + Neck + Head” 结构,但进行了深度优化:
3.1 Backbone:Modified CSPDarknet + E-ELAN
- 基于 CSPDarknet 改进,引入 E-ELAN(Extended ELAN)
- E-ELAN 通过分组卷积 + 拼接扩展计算路径,不增加推理延迟,但增强特征多样性
- 使用 MP-1 Conv(MaxPool + Conv)替代 stride=2 卷积,保留更多空间信息
3.2 Neck:改进 PANet
- 融合自顶向下与自底向上路径
- 引入 concatenation-based skip connections,增强多尺度特征融合
3.3 Head:Anchor-Based 多尺度输出
- 三个输出层(P3/P4/P5),对应小/中/大物体
- 每层预测 3 个 anchor boxes(共 9 个,由 k-means 聚类获得)
- 输出:(x, y, w, h, objectness, class_probs)
与 YOLOv5 类似,但结构更高效。
4. 关键技术详解
4.1 可训练的 Bag-of-Freebies(Trainable BoF)
传统 BoF(如 Mosaic、MixUp)是固定的。YOLOv7 提出可学习的增强与分配机制:
- Dynamic Label Assignment:根据预测质量动态分配正样本
- Implicit Knowledge in Auxiliary Head:辅助头不参与最终推理,但通过隐式表示(如矩阵变换)引导主干学习
4.2 Coarse-to-Fine 动态标签分配
- 同时考虑 主检测头(lead head) 和 辅助检测头(auxiliary head) 的预测
- 构建 cost matrix(含分类 loss + IoU + objectness)
- 使用 SimOTA 或 Hungarian Matching 选择最优正样本
- 实现“粗到精”的监督信号,提升收敛质量
4.3 模型缩放策略(Model Scaling)
- 针对 concatenation-based 网络(非 add-based 如 ResNet)设计新缩放规则
- 同时调整 depth(层数)、width(通道数)、resolution
- 衍生出 YOLOv7-Tiny / YOLOv7 / YOLOv7-X / YOLOv7-W6 / E6 / D6 / E6E 等多个版本
4.4 辅助训练头(Auxiliary Head)
- 在训练阶段添加一个额外的检测头
- 该头使用隐式表示模块(如 implicit knowledge layer)增强表达能力
- 推理时完全移除,零推理开销
- 作用:提供更强的监督信号,防止主干过拟合
5. 模型系列与性能(COCO test-dev)
| 模型 | 输入尺寸 | 参数量 | FLOPs | [email protected] | mAP@[0.5:0.95] | 速度(V100, FPS) |
|---|---|---|---|---|---|---|
| YOLOv5x | 640 | 86.7M | 205.7G | 65.7 | 50.7 | ~20 |
| YOLOv6-L | 640 | 77.1M | 214.0G | 65.8 | 51.8 | ~25 |
| YOLOv7 | 640 | 36.9M | 104.7G | 69.7 | 51.2 | ~35 |
| YOLOv7-X | 640 | 71.3M | 193.4G | 71.0 | 55.0 | ~25 |
| YOLOv7-W6 | 1280 | 51.0M | 501.2G | 73.3 | 57.0 | ~15 |
| YOLOv7-E6E | 1536 | 107.0M | 1372.0G | 75.0 | 58.8 | ~8 |
YOLOv7-X 以更低参数量超越 YOLOv5x 3.8 mAP@[0.5:0.95],且更快。
6. 训练策略
- 优化器:SGD with momentum
- 数据增强:Mosaic + MixUp + HSV + RandomAffine
- 正则化:DropBlock、EMA(指数移动平均)
- 损失函数:
- 分类:BCEWithLogitsLoss
- 定位:CIoU Loss
- 置信度:BCE Loss
- 多尺度训练:320–640(小模型)或 640–1280(大模型)
7. 优缺点分析
优点:
- SOTA 精度:在实时检测器中 mAP@[0.5:0.95] 最高
- 零推理开销的训练增强:Aux head、implicit knowledge 不影响部署
- 高效缩放:覆盖从边缘到服务器的全场景
- 开源完整:提供 Darknet 和 PyTorch 实现
缺点:
- 训练复杂度高:需较大显存(YOLOv7-X 建议 32GB+)
- 大模型推理较慢:E6E 仅适合离线高精度场景
- 工程门槛较高:隐式模块调试困难
8. 总结
YOLOv7 是 YOLO 系列中训练策略最先进、精度最高的实时检测器之一。它通过可训练的 Bag-of-Freebies、动态标签分配和辅助隐式学习,在不增加推理负担的前提下,显著提升了模型性能。其提出的 E-ELAN 和模型缩放方法也为后续研究提供了新思路。
尽管 YOLOv8 等新框架在易用性上更胜一筹,YOLOv7 凭借其卓越的精度-速度平衡,仍是高要求工业场景(如自动驾驶、精密质检)的重要选择。
YOLOv8(You Only Look Once v8)
1. 概述
YOLOv8 由 Ultralytics 团队于 2023 年 1 月正式发布,是 YOLO 系列中首个统一多任务框架。作为 YOLOv5 的精神续作,YOLOv8 不仅全面优化了目标检测性能,更原生支持实例分割、姿态估计、图像分类、目标追踪四大任务,实现“一套代码,多任务覆盖”。
YOLOv8 的核心理念是:简化工作流、提升精度、强化部署能力。通过 Anchor-Free 架构、任务对齐分配器、解耦检测头等创新,在 COCO、Objects365 等基准上实现 SOTA 性能,同时提供极致友好的 Python API 与 CLI 工具链,成为当前工业界部署最广泛的目标检测框架之一。
注:YOLOv8 无学术论文,技术细节源自官方文档、源码及社区验证。
2. 核心创新
| 技术 | 说明 |
|---|---|
| Anchor-Free 检测头 | 移除 anchor boxes,简化超参,提升小目标检测能力 |
| Task-Aligned Assigner (TAL) | 动态标签分配:,对齐分类与定位质量 |
| C2f 模块 | 替代 C3,增强梯度流,提升特征融合效率 |
| Distribution Focal Loss (DFL) | 将边界框坐标建模为分布,提升回归精度 |
| 统一多任务架构 | 检测/分割/姿态/分类共享骨干,Head 按任务定制 |
| Ultralytics HUB | 云端训练、数据管理、模型部署一体化平台 |
3. 网络架构(检测任务)
3.1 Backbone:改进 CSPDarknet
- 使用 C2f 模块(跨阶段部分 + 多级特征融合)
- 比 C3 模块参数更少、梯度路径更丰富
- 内置 Shortcut 与多尺度特征拼接
- 下采样:stride=2 卷积(移除早期 Focus 层)
- 激活函数:SiLU(Swish)
3.2 Neck:PAN-FPN 增强版
- 自顶向下 + 自底向上双向融合
- 特征图尺度:P3 (80×80), P4 (40×40), P5 (20×20) @640×640 输入
3.3 Head:解耦 Anchor-Free
- 分类分支 与 回归分支 完全分离
- 每个 grid cell 预测:
- 分类分数(多标签 BCE)
- 边界框 (x, y, w, h) — 以 stride 为单位
- 无 objectness 置信度(由分类分数隐式表达)
分割任务:在 Head 增加 Mask Proto Head,输出原型掩码 + 系数
姿态任务:增加 关键点回归分支(x, y, visibility)
4. 关键技术详解
4.1 Task-Aligned Assigner (TAL)
-
正样本分配依据:
- :分类置信度, :预测框与 GT 重叠度
- $(\alpha, \beta) $:平衡超参(默认 1.0, 6.0)
-
动态选择 Top-k 高分样本作为正样本
-
解决分类-定位质量不一致问题,显著提升 AP
4.2 Distribution Focal Loss (DFL)
- 将边界框坐标建模为离散分布(如 16 维向量)
- 通过 Softmax + 积分计算最终坐标
- 优势:缓解边界框回归的“硬标签”问题,提升定位鲁棒性
4.3 多任务统一设计
| 任务 | 模型后缀 | Head 特性 |
|---|---|---|
| 目标检测 | yolov8n.pt |
Anchor-Free 检测头 |
| 实例分割 | yolov8n-seg.pt |
+ Mask Proto Head |
| 姿态估计 | yolov8n-pose.pt |
+ 关键点回归分支 |
| 图像分类 | yolov8n-cls.pt |
全局池化 + FC 层 |
5. 模型系列(COCO val2017)
| 模型 | 参数量 | FLOPs | [email protected] | mAP@[0.5:0.95] | 推理速度 (V100) |
|---|---|---|---|---|---|
| YOLOv8n | 3.2M | 8.7G | 50.6 | 37.3 | ~1.0 ms |
| YOLOv8s | 11.2M | 28.6G | 56.1 | 44.9 | ~1.5 ms |
| YOLOv8m | 25.9M | 78.9G | 59.0 | 49.9 | ~2.5 ms |
| YOLOv8l | 43.7M | 165.2G | 60.6 | 52.9 | ~3.5 ms |
| YOLOv8x | 68.2M | 257.8G | 61.2 | 53.9 | ~5.0 ms |
对比 YOLOv5x:YOLOv8x mAP@[0.5:0.95] +3.2,速度提升 25%
6. 多任务性能亮点
实例分割(COCO val)
- YOLOv8x-seg:mAP_mask = 44.1(超越 Mask R-CNN 5.2 点)
- 推理速度:~8 ms(V100),支持实时分割
姿态估计(COCO val)
- YOLOv8x-pose:AP_keypoints = 72.8
- 支持 17 关键点(COCO)或自定义关键点数量
图像分类(ImageNet-1k)
- YOLOv8x-cls:Top-1 Acc = 82.7%
- 推理速度:~0.8 ms(batch=1, V100)
8. 优缺点分析
优势
- 真正的多任务框架:检测/分割/姿态/分类开箱即用
- 极致易用性:统一 CLI + Python API,5 行代码完成训练/推理
- 部署全覆盖:支持 ONNX, TensorRT, CoreML, TFLite, OpenVINO, RKNN
- 活跃生态:HUB 云平台、模型动物园、社区插件(SAM 集成等)
- 精度-速度均衡:小模型(n/s)适合边缘,大模型(l/x)适合高精度场景
局限
- 大模型(X)对显存要求高(训练需 24GB+)
- Anchor-Free 对极端长宽比目标泛化略弱于 Anchor-Based
- 无官方学术论文,部分设计细节需源码验证
9. 与 YOLO 系列对比
| 特性 | YOLOv5 | YOLOv6 | YOLOv7 | YOLOv8 |
|---|---|---|---|---|
| Anchor | ✓ | ✗ | ✓ | ✗ |
| 多任务 | ✗ | ✗ | ✗ | ✓ (检测/分割/姿态/分类) |
| 标签分配 | Static | SimOTA | Dynamic | Task-Aligned Assigner |
| 损失函数 | CIoU | SIoU | EIoU | DFL + CIoU |
| 部署工具链 | 良好 | 一般 | 良好 | 极佳(Ultralytics Engine) |
| 社区活跃度 | 高 | 中 | 中 | 极高 |
10. 总结
YOLOv8 代表了 YOLO 系列从“单一检测器”向“通用视觉基础模型”的关键跃迁。它通过架构精简(Anchor-Free)、训练优化(TAL+DFL)、任务统一(Detection+Segmentation+Pose+Classification) 三大支柱,在保持 Ultralytics 一贯易用性的同时,将精度与部署效率推向新高度。
无论是科研快速验证、工业级部署,还是边缘设备落地,YOLOv8 凭借其模块化设计、完善文档与活跃社区,已成为 2023–2026 年计算机视觉领域的事实标准工具。随着 Ultralytics HUB 与持续更新(v8.1/v8.2+),其生态影响力仍在快速扩展。
YOLOv9(You Only Look Once v9)技术文档
1. 概述
YOLOv9 由 Alexey Bochkovskiy 团队(YOLOv4/v7 作者)与 Chien-Yao Wang 于 2024 年 1 月正式提出,发表在论文《YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information》中。作为 YOLO 系列的突破性迭代,YOLOv9 首次系统性解决深度神经网络中的信息瓶颈问题,提出 可编程梯度信息(PGI) 与 通用高效层聚合网络(GELAN),在保持实时推理速度的同时,在 COCO、VisDrone 等多个基准上刷新 SOTA 记录。
YOLOv9 的核心理念是:让网络“学会学习”——通过设计可传递完整梯度信息的架构,使浅层特征也能获得高质量监督信号,显著提升小目标检测与密集场景表现,同时避免传统深度监督(Deep Supervision)带来的信息损耗。
2. 核心创新
| 技术 | 说明 |
|---|---|
| PGI(Programmable Gradient Information) | 可编程梯度信息:构建辅助可逆路径,将完整梯度信息“编程”回浅层,解决信息瓶颈 |
| GELAN(Generalized ELAN) | 通用高效层聚合网络:兼容 Conv/DWConv 等计算单元,兼顾精度与硬件效率 |
| CSP-ELAN 模块 | 跨阶段部分连接 + ELAN,增强梯度流,减少重复计算 |
| 新型模型缩放策略 | 针对 GELAN 架构设计深度/宽度/分辨率联合缩放规则 |
| 轻量级辅助头设计 | 仅训练时启用,推理零开销,强化梯度传播 |
3. 网络架构
3.1 整体框架
1 | Input → [GELAN Backbone] → [Enhanced PAN Neck] → [Task-Specific Heads] |
3.2 Backbone:GELAN
- 核心思想:将 ELAN(Efficient Layer Aggregation Network)泛化为可适配任意计算模块的框架
- 结构特点:
- 采用 CSP-ELAN 模块:输入通道分两路,一路经多级 ELAN 处理,一路直连
- 支持灵活替换基础计算单元(Standard Conv / Depthwise Conv / Ghost Conv)
- 梯度路径显式设计,避免信息压缩
- 优势:在相同 FLOPs 下,比 YOLOv7 的 E-ELAN 提升 1.5–2.0 mAP
3.3 PGI 辅助路径(训练专属)
- 在骨干网络中嵌入可逆辅助分支
- 该分支:
- 接收深层监督信号
- 通过可学习映射将完整梯度“编程”回浅层特征
- 推理时完全移除,零延迟开销
- 解决传统 Deep Supervision 中因多次下采样导致的梯度稀释问题
3.4 Neck 与 Head
- Neck:增强版 PANet,融合 PGI 优化后的多尺度特征
- Head:
- 检测:Anchor-Free + Task-Aligned Assigner(继承 YOLOv8 优化)
- 分割/姿态:扩展专用 Head(社区实现)
- 输出:分类分数 + 边界框(DFL 回归)
4. 关键技术详解
4.1 可编程梯度信息(PGI)
- 问题:传统深度监督中,辅助头预测的浅层特征因感受野小、语义弱,导致梯度质量低
- PGI 方案:
- 构建可逆辅助路径(含上采样与特征重建模块)
- 将主干深层高质量特征“映射”回浅层空间
- 通过可学习参数动态调整梯度回传强度
- 效果:浅层特征获得与深层等效的监督质量,小目标 AP 提升 4.2%
4.2 GELAN 架构优势
| 特性 | 说明 |
|---|---|
| 硬件友好 | 避免不规则操作(如大核 DWConv),适配 Tensor Core/NPU |
| 模块解耦 | 计算单元(Conv/DWConv)与连接策略(ELAN)分离,便于定制 |
| 梯度高效 | CSP + ELAN 双重设计,缓解梯度消失,支持更深网络 |
4.3 模型缩放策略
- 提出 GELAN-specific scaling rules:
- 深度缩放:调整 ELAN 模块堆叠数
- 宽度缩放:按比例调整通道数(遵循通道对齐原则)
- 分辨率缩放:320 → 1280 动态适配
- 衍生模型:YOLOv9-T/S/M/C/E(C: Compact, E: Extra-large)
5. 性能表现(COCO test-dev)
| 模型 | 输入尺寸 | 参数量 | FLOPs | [email protected] | mAP@[0.5:0.95] | 速度 (V100) |
|---|---|---|---|---|---|---|
| YOLOv8x | 640 | 68.2M | 257.8G | 61.2 | 53.9 | ~5.0 ms |
| YOLOv7-E6E | 1536 | 107.0M | 1372G | 75.0 | 58.8 | ~125 ms |
| YOLOv9-C | 640 | 25.4M | 71.1G | 67.1 | 53.0 | ~4.2 ms |
| YOLOv9-E | 1280 | 57.8M | 239.5G | 73.5 | 55.0 | ~18.3 ms |
小目标检测(COCO APₛ)
| 模型 | APₛ |
|---|---|
| YOLOv8x | 38.5 |
| YOLOv7-E6E | 41.2 |
| YOLOv9-E | 45.7 |
YOLOv9-E 以更低 FLOPs 超越 YOLOv7-E6E 1.5 mAP@[0.5:0.95],小目标检测提升显著
VisDrone2019(无人机场景)
| 模型 | AP |
|---|---|
| YOLOv8x | 28.3 |
| YOLOv9-E | 34.1 |
6. 训练与部署
训练策略
-
优化器:SGD + Cosine LR decay
-
增强:Mosaic + MixUp + Copy-Paste(小目标专用)
-
PGI 启用:仅训练阶段激活辅助路径
-
硬件要求:YOLOv9-E 建议 48GB+ GPU 显存
-
支持格式:ONNX, TensorRT, OpenVINO, CoreML, TFLite
-
推理库:提供 C++/Python SDK(含预处理/后处理)
7. 优缺点分析
优势
- 突破信息瓶颈:PGI 使浅层特征获得高质量监督,小目标检测显著提升
- 架构通用性强:GELAN 可适配多种硬件与计算单元
- 精度-效率新标杆:同等速度下 mAP 超越所有实时检测器
- 训练-推理解耦:辅助路径零推理开销
- 开源完整:官方提供 PyTorch 训练代码 + 多平台部署方案
局限
- 训练复杂度高(需管理辅助路径)
- 大模型(E)对训练资源要求苛刻
- 多任务支持需社区扩展(官方聚焦检测)
9. 与 YOLO 系列演进对比
| 版本 | 核心突破 | 信息流优化 | 小目标 APₛ | 定位 |
|---|---|---|---|---|
| YOLOv5 | 工程易用性 | ✗ | 35.1 | 工业部署首选 |
| YOLOv6 | Rep 重参数化 | ✗ | 36.8 | 边缘设备优化 |
| YOLOv7 | 可训练 BoF | △(辅助头) | 39.5 | 训练策略创新 |
| YOLOv8 | 多任务统一 | ✗ | 38.5 | 全场景框架 |
| YOLOv9 | PGI + GELAN | ✓(可编程梯度) | 45.7 | 信息瓶颈突破 |
△:辅助头提供监督但未解决梯度稀释;✓:PGI 主动重构高质量梯度回传路径
10. 总结
YOLOv9 是 YOLO 系列中首次从信息理论层面重构检测架构的里程碑工作。它不再局限于模块堆叠或训练技巧优化,而是直面深度网络的根本挑战——信息瓶颈,通过 PGI 技术让网络“学会传递有效学习信号”,实现精度与效率的双重飞跃。
在无人机巡检、卫星遥感、密集人群分析等小目标密集场景中,YOLOv9 展现出不可替代的优势。其提出的 GELAN 架构与 PGI 思想,也为后续视觉基础模型设计提供了全新范式。
🌐 开源地址:https://github.com/WongKinYiu/yolov9
📄 论文链接:https://arxiv.org/abs/2402.13616