
GRPO算法公式详解
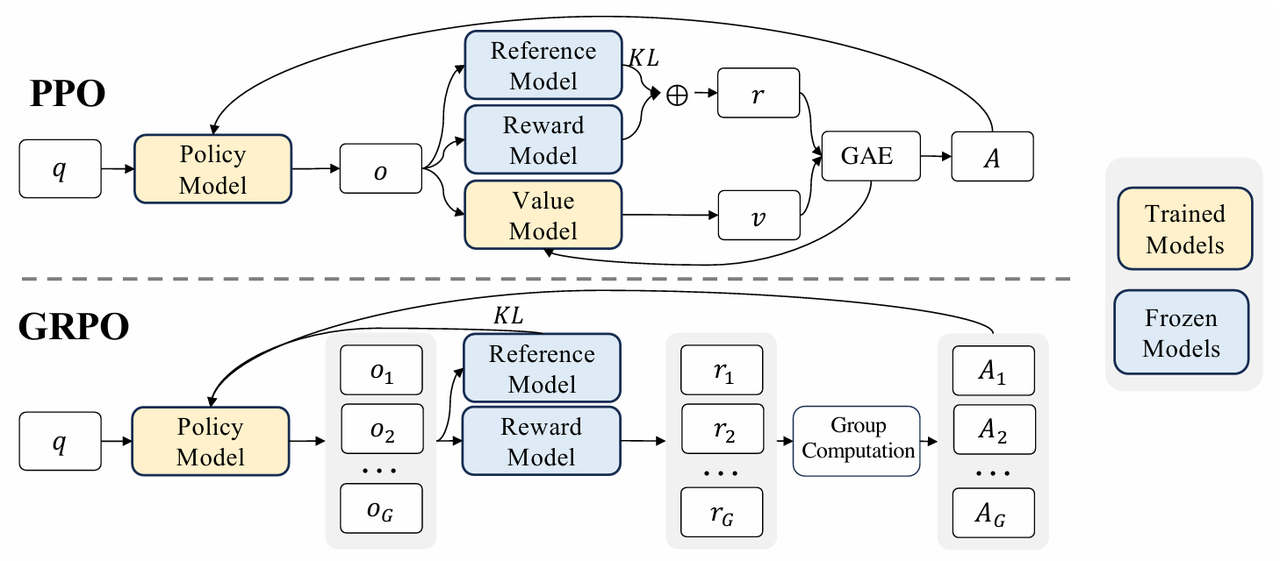
GRPO(Group Relative Policy Optimization) 算法是在 PPO 基础上进行扩展,特别适用于多响应生成场景(如对话系统、多候选回复排序、A/B 测试等),其中模型需要为同一个 query 生成多个候选输出(称为“组”或“group”),并根据某种相对奖励机制进行优化。
简单公式
完整公式:
注意:这里 $$\hat{A}_{i,t}$$ 是归一化/相对优势函数,区别于标准 PPO 中的绝对优势$$A_t$$;同时加入了 KL 正则项来约束策略与参考策略的距离。
逐部分详解
第一部分:期望采样 —— 数据来源
-
从查询分布
P(Q)中采样一个 queryq。 -
在旧策略 $$π_{θ_{old}}$$ 下,为该 query 生成 G 个候选输出序列
{o₁, o₂, ..., o_G}。-
每个 $$o_i$$ 是一个完整的 token 序列,比如一条回复、一段文本。
-
这是 GRPO 的核心创新点之一:一次采样多个候选,用于后续的“组内比较”。
-
相比标准 PPO 只采样一个轨迹,GRPO 利用“组内对比”构建更丰富的监督信号。
第二部分:组内平均 + 序列平均
-
对 G 个候选输出的损失做平均$$\frac{1}{G} \sum_{i=1}^G$$。
-
对每个候选输出 $$o_i$$,对其每个时间步
t的损失做平均$$\frac{1}{|o_i|} \sum_{t=1}^{|o_i|}$$。 -
这确保了不同长度、不同数量的候选在目标函数中被公平对待。
第三部分:裁剪目标函数(核心 PPO 部分)
其中:
-
r_{i,t}(\theta) = \dfrac{\pi_\theta(o_{i,t} | q, o_{i,
关键概念:什么是 $$\hat{A}_{i,t}$$?为什么叫“相对优势”?
在标准 PPO 中,$$A_t$$ 衡量的是“当前动作相对于平均表现的好坏”。但在 GRPO 中,我们有多个候选输出,因此可以利用它们之间的相对排序或评分来定义优势。
常见的 $$\hat{A}_{i,t}$$ 构造方式:
方法一:基于成对比较(Pairwise Ranking)
-
假设我们有一个打分函数 $$R(o_i | q)$$(如人类偏好模型、奖励模型),给出每个候选的得分。
-
对第 i 个候选,其优势可定义为:
→ 即:该候选得分减去组内平均得分。
方法二:基于排名(Rank-based Advantage)
-
根据得分对 G 个候选排序,第 i 名得分为
rank(i)。 -
优势函数可设为:
方法三:基于交叉熵或 softmax 归一化
- 将得分转换为概率分布:
- 优势函数可设为:
无论哪种方式,核心思想都是:不是绝对好坏,而是“在这个组里相对好坏”。
第四部分:KL 正则项 —— 策略约束
-
-
是正则化系数,控制约束强度。
-
是一个参考策略(reference policy),通常是初始策略、SFT(Supervised Fine-Tuning)策略,或人类数据分布。
-
KL 散度衡量新策略 与参考策略 的差异。
-
负号表示:我们希望最小化 KL 散度 → 让新策略不要偏离参考策略太远。
作用:
-
防止过度优化导致语言模型“跑偏”(如产生无意义、重复、攻击性内容)。
-
保留 SFT 阶段学到的语言能力、格式、风格等。
-
类似于 RLHF 中常用的 “KL penalty”,避免策略崩溃。
GRPO 的设计哲学总结
实际应用场景举例
场景 1:对话系统中的多候选回复排序
-
输入:用户问题
q -
输出:模型生成 3 条回复
o₁, o₂, o₃ -
奖励模型给出分数:
R(o₁)=0.8, R(o₂)=0.6, R(o₃)=0.9 -
相对优势:
-
Â₁ = 0.8 - 0.766 ≈ 0.034 -
Â₂ = 0.6 - 0.766 ≈ -0.166 -
Â₃ = 0.9 - 0.766 ≈ 0.134
-
-
用这些优势更新策略,鼓励生成高分回复,抑制低分回复。
场景 2:RLHF 中的人类偏好学习
-
人类标注者对两个回复 A 和 B 进行排序(A > B)
-
可构造成 G=2 的组,优势函数基于偏好关系。
-
GRPO 自然支持这种成对比较数据。
与 PPO 的对比
为什么 GRPO 更适合语言模型微调?
-
人类反馈通常是相对的(“A 比 B 好”),而非绝对分数。
-
语言模型输出多样性强,单次采样难以覆盖所有可能性,多候选能提供更丰富信号。
-
避免策略崩溃:KL 正则防止模型脱离人类语料分布。
-
高效利用数据:一次采样多个候选,提升数据利用率。
总结一句话
GRPO 是 PPO 的增强版,专为多候选生成任务设计:通过组内相对优势函数和 KL 正则项,在保持语言质量的同时,有效利用人类偏好或奖励模型进行策略优化。
延伸阅读建议
-
原始论文:Group Relative Policy Optimization for Efficient Preference Learning(假设是你引用的论文,若非官方名称,可能是某团队提出的方法,但结构符合主流改进方向)
-
相关算法:
-
DPO(Direct Preference Optimization)—— 不用强化学习,直接优化偏好
-
IPO(Implicit Preference Optimization)—— 类似 GRPO,但用隐式梯度
-
RLAIF(Reinforcement Learning from AI Feedback)—— 用 AI 代替人类打分
-