
Multi-Head Latent Attention (MLA)详解
-
论文 DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
-
github: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
参考博客:
-
https://bruceyuan.com/post/hands-on-deepseek-mla-projection-absorption.html
-
https://github.com/madsys-dev/deepseekv2-profile/blob/main/workspace/blog/optimizing-mla.md
1 | 洞见: |
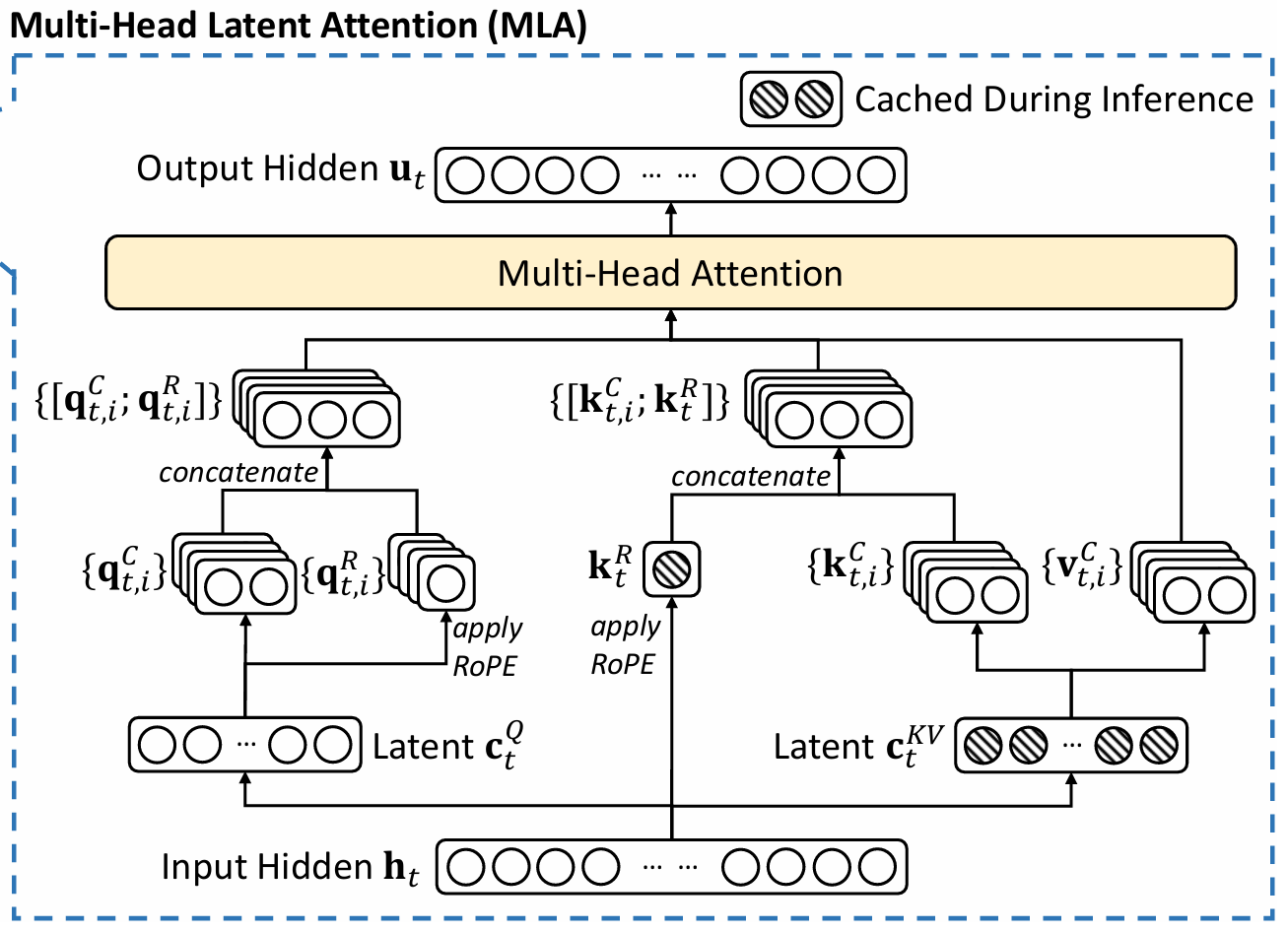
1. Multi-Head Attention (MHA) 回顾
标准的多头注意力:表示嵌入维度,表示注意力头的数量,表示每个头的维度, 表示在注意力层中第t个token的注意力输入。
标准MHA机制通过三个矩阵分别生成输入的查询向量、键向量和值向量。公式如下:
接下来,,,将被切分成个头,用于多头注意力计算:
其中:
- 是第 个 token 的第i个头的 query、key、value 向量。
- 是注意力头数,QKV分头前的特征维度为,分头后每个头的维度是 。
公式含义:将原始的 按列切分成 个头的子向量。
每个头的注意力计算公式为:
最后拼接所有头的输出,再做输出投影:
其中 是输出映射矩阵。
推理时问题:
- 所有 key 和 value 需要缓存,KV cache大小为 ( 为序列长度),当 batch size 和 很大时会占用大量显存。
2. Low-Rank Key-Value Joint Compression(低秩 KV 联合压缩)
MLA 核心是通过低秩联合压缩减少 KV cache大小。
-
压缩输入:
将输入 压缩到KV低维共享表示 :
- :压缩后的 latent 表示,。
- :降维矩阵,D的含义是降维down_sample。
-
解码 key 和 value:
从 解码出 key 和 value:
- :升维矩阵,U的含义是升维up_sample。
-
**低秩压缩后的注意力权重计算方式 **:
- 最后的输出:
多头注意力相当于把 注意力权重从一维向量变为了二维向量,shape: (seq_len,) -> (seq_len, head_num),但本质上还是一个张量,只是得到这个张量的方式注意力机制计算比较复杂。
优势:
- 推理时仅需缓存 (每 token 只需 维),KV 缓存大小从 缩减到 。
- 可将 与 合并,将 与 合并,无需显式生成或存储 key/value。
矩阵合并分析:
上面公式看似需要使用重新生成历史的KV,但是通过权重吸收(合并)可以将重新生成的步骤合并其他向量的投影中,从而无需真正重新生成。
与 的合并,维度变换是 ,吸收后是 ,如果是原始的MHA不进行维度压缩,可以看出来吸收后相比MHA计算量减少,不吸收则增大计算量。
与 合并,维度变换是 , 吸收后是,同样吸收后相比MHA计算量减少,不吸收则增大计算量。
3. Low-Rank Query Compression(低秩 Query 压缩)
虽然压缩 Query 不能减少 KV 缓存,但是也能节省计算。
- 压缩 Query:
- :压缩后的 query 表示,。
- ,:降维和升维矩阵。
作用:
- 降维后再升维,减少全连接计算量,尤其适用于输入维度 较大的场景。
4. Decoupled Rotary Position Embedding(解耦 RoPE)
背景
前面的推理没有考虑位置编码,如果考虑RoPE位置编码,会发现权重吸收和位置编码不兼容:
前面 与 可以合并,是因为$(WQ)\top 𝑊^{𝑈𝐾} (WQ)\top R_{j-t} 𝑊^{𝑈𝐾}tR_{j-t}$,即随推理过程中query的位置变化而变化,导致旧的缓存不能直接使用,所以无法直接合并。
为什么GQA的低秩投影没有受RoPE影响,因为GQA只减少了头数,计算时又恢复了头数,但是隐式恢复头数直接通过广播实现,不涉及特征维度改变序列长度改变;而MLA减小的是每个头的特征维度,计算时为了避免增加计算量,只能隐式恢复特征维度,即需要借助权重吸收,而两个权重之间又夹着RoPE,没办法权重吸收。
RoPE(Rotary Position Embedding)对 key 和 query 都是位置敏感的。
若直接将 RoPE 应用于压缩后的 key,升维矩阵 无法与 合并,影响推理效率?
一个简单的逻辑应该是把位置编码都应用到压缩后的特征上。
原因
- RoPE 是依赖位置的旋转矩阵,矩阵乘法不满足交换律。
- 若在升维后的 key 上应用 RoPE,需重新计算所有历史 key 的位置编码,无法仅用缓存恢复。
解决方案
将 query 和 key 分为两部分,一部分就用MLA不使用RoPE 位置编码,另一部分用MQA使用位置编码:
-
对 query 和 key 分别应用 RoPE:
将输入的查询内容向量 通过矩阵 投影到 RoPE 编码后的空间,得到分离后的旋转位置编码查询向量 ,并按多头分块。
将隐藏状态 $ h_t $ 通过矩阵 投影,并应用 RoPE 得到分离后的旋转位置编码键向量$ k^R_t $。
-
拼接压缩部分和 RoPE 部分:
将内容查询向量与旋转位置编码查询向量进行拼接,得到最终的第 个头的查询向量。
将内容键向量与旋转位置编码键向量拼接,得到最终的第个头的键向量。
-
注意力计算:
通过点积计算第 个头在时间步 的查询向量与历史键向量的相关性,除以 进行缩放,然后使用 Softmax 得到注意力权重,对对应的值向量 进行加权求和。
-
最终输出:
将所有头的输出 拼接起来,并通过输出权重矩阵 得到最终的输出向量 。
其中 和$ W^{KR} \in \mathbb{R}{dR_h \times d}RoPE(·)[\cdot ;\cdot]$表示拼接操作。在推理阶段,分离的键向量也需要被缓存。因此,MLA需要一个包含 元素的 KV 缓存。
参数说明:
- :RoPE 部分的维度。
- 推理时只需缓存 (大小约为 )。
5. 总结 MLA 思路
MLA 的核心目标是降低推理时的显存占用和计算延迟,同时保持注意力效果。具体方法包括:
- 低秩联合压缩 KV:通过共享压缩表示 减少 KV 缓存大小。
- 低秩 Query 压缩:减少 Query 的计算量。
- 解耦 RoPE:在保留位置编码效果的同时,使压缩策略兼容 RoPE,避免破坏缓存复用。
最终效果:
- 显存占用从 降至 。
- 计算效率提升,适用于大规模模型部署。

