
Rethinking Table Recognitionusing Graph Neural Networks
会议: ICDAR 2019
论文地址:https://arxiv.org/abs/1905.13391
github: https://github.com/shahrukhqasim/TIES-2.0
[TOC]
摘要
文档结构分析,例如区域分割和表格识别,是文档处理中的复杂问题,并且是一个活跃的研究领域。深度学习在解决各种计算机视觉和机器学习问题方面的近期成功尚未反映在文档结构分析中,因为传统的神经网络不适合该问题的输入结构。本文提出了一种基于图网络的架构作为标准神经网络更好的替代方案来识别表格。我们主张图网络对于这些问题是一种更自然的选择,并探索了两种基于梯度的图神经网络。我们的提出的架构结合了卷积神经网络用于视觉特征提取以及图网络用于处理问题结构的好处。我们在实验上证明,与基线相比,我们的方法具有显著的优势。此外,我们还指出大规模数据集缺乏是结构分析领域深度学习研究的主要障碍,并提出了一个针对表格识别的新大规模合成数据集。最后,我们开源了我们的数据生成和图网络训练框架实现,以促进这一方向上的可重复研究。
**关键词:表格识别;结构分析;图神经网络;文档模型;图形模型;数据集 **
I. 前言
结构分析是文档处理中最重要方面之一。它包括物理和逻辑布局分析,也包括对复杂结构化布局的解析或识别,如表格、收据和表单等。尽管在文档物理和逻辑布局分析方面已经做了很多研究工作,但仍然有很多空间可以为解析这些结构化布局做出贡献,例如表格。表格提供了一种直观且自然的方式将数据以人类易于理解的形式呈现出来。基于其重要性和难度水平,表格结构分析吸引了大量研究人员在这个领域做出贡献。
表格检测和识别是一个老问题,研究始于九十年代末。最初的工作之一是由Kieninger等人完成的[1]。他们使用基于启发式算法的单词边界框进行自下而上的方法。后来,许多手工制作特征的方法被引入,包括[2],[3],[4]和[5],这些方法依赖于定制设计的算法。Zanibbi等人[6]的综述对当时表格检测和结构识别算法进行了全面的调查。[7]提出了一个方法,该方法将每个单元格分为标题、标题或数据单元格。Shafait等人[8]做了大量工作,在那里他们引入了不同的性能度量来表征表格检测问题。这些方法不是基于数据驱动的,并且它们对表格结构做出了强烈的假设。
Chen等人[9]使用支持向量机和动态规划检测手写文档中的表格。Kasar等人[10]也使用SVM在规则线上检测表格。Hao等人[11]使用松散的规则提取表格区域,并使用CNN对区域进行分类。他们还使用PDF文本信息来改进模型结果。Rashid等人[12]使用每个单词的位置信息,通过密集神经网络将其分类为表格或非表格。
从2016年开始,研究开始转向使用深度学习模型来解决挑战。在2017年,许多论文使用对象检测或分割模型对表格进行检测和解析。Gilani等人[13]利用图像中的距离变换编码信息,并应用Faster RCNN[14]到这些图像上。Schreiber等人[15]也使用Faster RCNN进行表格检测和行列的提取。对于解析,他们将对象检测算法应用于垂直拉伸文档图像。利用表格属性,Arif等人[16]提出通过彩色代码文档图像以区分数值文本并应用更快的RCNN提取表区域。同样地,Siddique等人[17]提出了一个端到端的Faster-RCNN管道用于表格检测任务,并使用变形卷积神经网络作为特征提取器,因为它可以根据输入调整其接收域的能力。He等人[19]将文档图像分为三类:文本、表格和图表。他们提出使用条件随机场(CRF)来改善基于轮廓边缘检测网络输出的全卷积网络(FCN)的结果。Kavasidis等人[20]使用全卷积神经网络提取的突出性地图上的CRFs来检测表格以及不同类型的图表。
尽管许多研究人员已经表明基于目标检测的方法对表检测和识别的效果很好,将解析问题定义为对象检测问题很难,尤其是文档是通过相机拍摄的并且包含透视畸变。像 [15] 这样的方法部分解决了这个问题,但它仍然不是一个自然的方法。这也使得使用进一步特征变得更加困难,这些特征可以独立提取,例如语言特征可能暗示存在表格的存在。
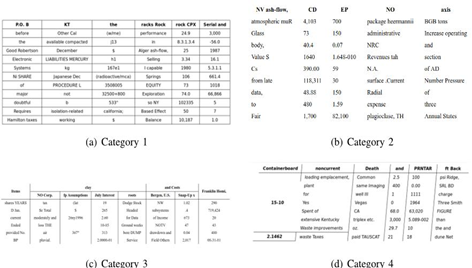
图1:不同难度类别的图像。第1类图像是没有合并且有格线的普通图像。第2类添加了不同的边框类型,包括偶尔缺少分界线。第3类是最难引入单元格和列合并的类别。第4类模型通过线性透视变换拍摄的图像。
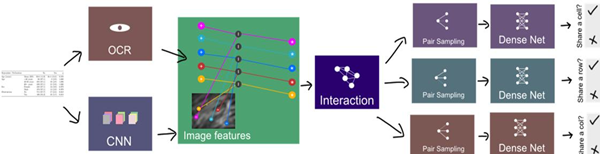
图2:我们的架构的图形表示。对于文档图像,使用CNN模型提取特征映射,并且使用OCR引擎或oracle(+)提取单词的位置。相应的图像特征与单词位置结合形成输入特征(*)。将输入特征应用到交互网络以获得代表性的特征。对于每个单词,单独对单元格、行和列进行采样。每个样本对的代表性特征再次连接并用作密集网络的输入。这些密集网络根据共享行、列和单元格的不同而不同。在训练期间仅进行采样,在推理期间每对单词进行分类。
在本文中,我们使用图论来定义问题,并将其应用于图神经网络。Scarselli等人[21]对图神经网络的最初研究之一是基于收缩映射提出了一种全面的图模型。近年来,由于计算能力的增加和新方法的引入,它们获得了很大的关注。许多值得注意的工作包括[22],[23],[24]。Battaglia等人[25]认为,关系归纳偏置是实现类人智能的关键,并展示了图神经网络对其至关重要。
文档处理中使用图(机器学习)并不是新鲜事。已经发表了许多论文,其中采用基于图的模型来解决各种问题。Liang等人[26]引入了一种类似于树状结构的文档解析层次结构。王[27]的工作获得了很大的流行度,并且被许多研究人员之后所使用。Hu等人[28]介绍了一个全面的图模型,其中包括一个有向无环图(DAG)以及对表格元素的各种详细定义。最近,Koci等人[29]提出了一种方法,在该方法中他们将信息编码为图形式。随后,他们使用了新提出的基于规则的删除和征服算法。Bunke等人[30]提供了关于文档分析背景下不同图技术的详细分析。这些方法对底层结构做出了强烈的假设,这与深度学习的哲学相矛盾。尽管我们不是第一个使用图来处理文档的人,但据我们所知,我们是第一个将图神经网络应用于我们的问题(表格识别)中。我们在表格识别问题上进行了实验,然而,这个新的问题定义适用于文档结构分析中的各种其他问题。我们的方法有两个优点。首先,它更加通用,因为它不作任何关于结构的强假设,并且与人类如何解读表格非常接近,即通过匹配数据单元格到其标题。其次,它允许我们利用最近有很多推动作用的图神经网络。
特别地,我们做出了以下贡献:
-
将表格识别问题转化为与图神经网络兼容的图问题。
-
设计了一个新颖的可微分架构,该架构从图像特征提取的卷积神经网络和高效交互的图神经网络中受益。
-
介绍一种基于蒙特卡洛的新技术,以减少训练所需的内存要求。
-
通过引入合成数据集来填补大规模数据集的空白。
-
在两个最先进的基于图的方法上运行测试,并实验证明它们比基线网络表现更好。
II. 数据集
目前,研究社区已经发布了几个表格检测和结构识别的数据集,包括UW3、UNLV [31] 和ICDAR 2013表格竞赛数据集 [32]。然而,这些数据集的规模有限。这可能会导致深度神经网络过拟合,并且导致较差的一般化能力。许多人尝试了诸如转移学习等技术,但这些技术无法完全抵消大规模数据集的实用性。
我们提供了一个合成生成的大型数据集,该数据集分为四个类别,如图1所示。为了生成这个数据集,我们使用了Firefox和Selenium来渲染合成生成的HTML。我们注意到合成数据集生成并不是新的,并且类似的工作[2]已经做过。尽管从我们的数据集中很难泛化算法到真实世界中,但数据集为研究不同的算法提供了标准基准,直到创建大规模的真实世界数据集为止。我们也发布了我们的代码以生成进一步的数据,如果需要的话。
III. 图模型
考虑到表格识别的问题,将真实值定义为三个图,其中每个单词是一个顶点。这三个图的邻接矩阵分别代表了这三种共享关系,即行、列和单元格共享。因此如果两个顶点共享一行,即这两个词属于同一行,则这些顶点被认为是相邻的(同样适用于单元格和列共享)。
深度模型的预测也是以三个邻接矩阵的形式进行。在获得邻接矩阵后,通过解决行和列的最大子集问题以及单元格的连通分量问题,可以重建完整的单元、行和列。如图3所示。
该模型不仅适用于表格识别问题,还可以用于文档分割。在这种情况下,如果两个顶点(可以是单词)共享相同的区域,则它们相邻。这些区域也可以通过最大子图问题进行重建。
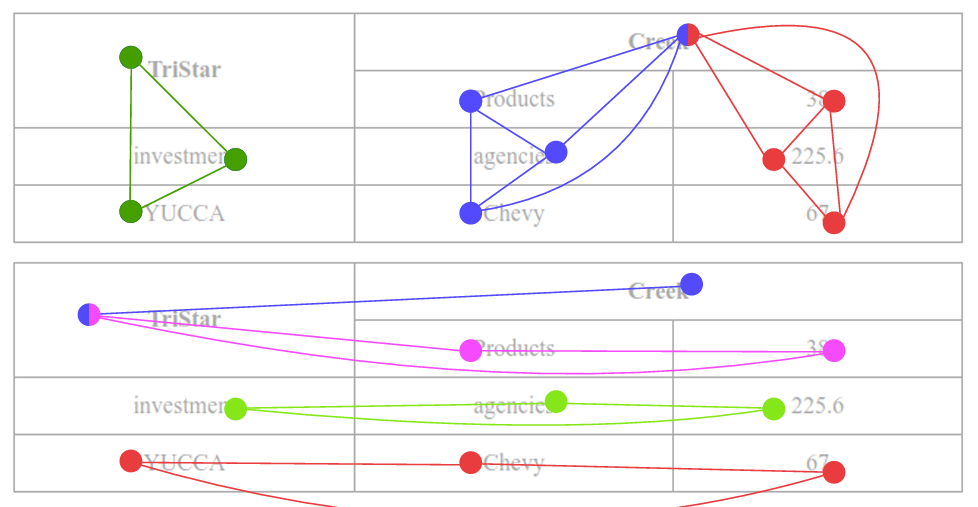
图3:使用最大子集重构结果的列和行段。上图显示了列子集,下图显示了行子集。注意这两个图中的合并顶点,它属于多个子集。
IV、方法
所有测试模型都遵循相同的父模式,如图2所示,分为三个部分:用于提取图像特征的卷积神经网络、用于顶点之间通信的交互网络以及分类部分,该部分将每个三张图中的每对顶点标记为相邻或不相邻(类0或类1)。
前向传播的算法也给出在算法1中。它接受图像( ——其中h,w和c分别表示输入图像的高度、宽度和通道数),位置特征( ——其中v代表顶点的数量)和其他特征。此外,在训练过程中还接受每个顶点的样本数量 以及三个邻接矩阵(, 和 )。所有参数函数都用表示,非参数函数用表示。如果所有的参数函数都是可微分的,则整个架构也是可微分的,并且因此与反向传播兼容。
位置特征包括每个顶点的上左角和下右角坐标。其他特征仅包含单词在我们情况下的长度。然而,在实际数据集中,自然语言特征(34)也可以附加,这可能提供额外的信息。
1)卷积神经网络:一个卷积神经网络()以图像(I)为输入,并且作为输出,它生成相应的卷积特征(—— 和 分别表示卷积特征映射的宽度、高度和通道数)。为了保持参数计数低,我们设计了一个浅层CNN;然而,任何标准架构都可以用作其替代品。在CNN的输出端,进行一个聚集操作(),收集每个单词对应的卷积特征,这些特征对应于图像中的空间位置,并形成聚集特征()。由于卷积神经网络是平移不变的,这个操作效果很好。如果输出特征的空间维度与输入图像不相同(例如,在我们的案例中,它们被缩小了),则根据输入和输出维度的比例线性缩放收集位置。将卷积特征扩展到其余顶点特征()。
2)交互:在收集所有顶点特征后,它们被作为输入传递给交互模型()。我们测试了两种图神经网络来用作交互部分,分别是修改后的[35]和[36]。这些修改的网络分别称为DGCNN* 和GravNet*。除了这三种之外,我们也测试了一个基于全连接神经网络的基线密集网络(简称FCNN),它与上述三个模型具有大致相同的参数数量,以显示基于图的模型表现更好。对于这三个模型,我们将总参数数限制为100万,以便进行公平比较。这个参数数也包括前面CNN和后续分类密集网络的参数。输出是每个顶点的代表性特征(——r代表代表性特征的数量),用于分类。
3)运行时对偶采样:为每个单词对进行分类是一个内存密集型操作,其内存复杂度为。由于它会随着批处理大小线性增长,因此内存要求进一步增加。为此,我们采用了蒙特卡罗采样方法。索引采样函数表示为。该函数将为每个问题(单元格共享、行共享和列共享)的每个顶点生成固定数量的样本(s)。
统一采样高度偏向于类0。由于内存限制,我们不能使用大批次大小,因此统计数据不足以区分两个类别。为了处理这个问题,我们将采样分布()更改为每个顶点平均为每个顶点采样等数量的元素类0和类1。这可以通过在算法1中所示的方式轻松地矢量化实现。请注意,在算法中J表示一个全1矩阵。对于每个顶点的三个类,分别收集一组样本(,, $S_{cols}∈Z^{v×t} $。这些矩阵中的值代表每个顶点对样本的索引。然而,在推理过程中,我们不需要采样,因为我们不需要使用mini-batch方法。因此,我们对每个顶点对都这样做。所以,在训练期间 ,在推理期间 。

4)分类:在采样之后,将交互模型的输出特征向量()中的元素与采样矩阵中的元素进行拼接(),并将其与(, 和 )相乘。这些函数是参数化的神经网络。作为输出,我们得到三个集合的logits 、和。它们可以用于计算损失并通过函数反向传播,也可以用于预测类别,并形成最终的邻接矩阵。
V 结果
Shahab等人[37]定义了一组用于详细评估表格解析和检测结果的度量标准。他们定义了正确和部分检测的标准,并定义了一个规则来标记元素为未分割、过度分割和遗漏。在他们的标准中,有两个与我们的案例最相关,即检测到的真实正例占真实正例总数的比例(真阳性率)以及预测的元素中没有匹配项的个数(假阳性率)。在我们的案例中,如第三节所述,元素是簇。因此,真阳性率和假阳性率分别计算在三个图上(单元格、行和列),然后对整个测试集进行平均。这些结果见表I和表II。
此外,我们还引入了另一个措施,即完美匹配,如表III所示。如果所有三个预测的邻接矩阵都与地面真值中的相应矩阵完全匹配,则解析的表被标记为端到端准确。这是一个严格的指标,但它显示了由于类不平衡问题导致基于单个表元素计算的统计结果是多么误导性。
正如预期的那样,由于FCNN中没有顶点之间的交互,因此其性能不如图模型。但是请注意,在此网络中的顶点并非完全分离。它们仍然可以在卷积神经网络部分进行通信。这为将图神经网络进一步引入文档分析奠定了基础。
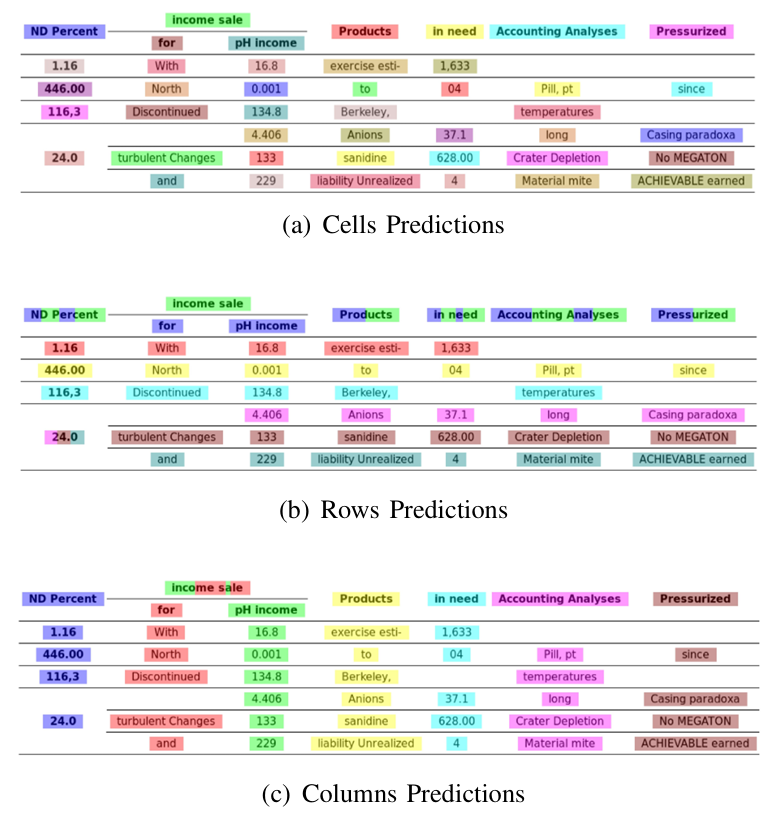
图4:显示DGCNN模型的预测(细胞、行和列)。图4 (a) 显示了细胞的预测。单个单元格中的所有单词都被分配相同的颜色。图4 (b) 显示了行的预测。属于同一行的单词被分配相同的颜色,跨多个行(簇)的单词被条纹色覆盖。同样地,图4 (c) 显示了列的预测。

图5:显示了随机选择的橙色顶点的DGCNN*模型预测(细胞、行和列邻居)。图5 (a) 显示了细胞预测。所有与随机顶点共享单元格的顶点都用绿色表示,而那些不相邻的则用蓝色表示。同样地,图5 (b) 和图5 (c) 分别显示了行和列共享图中的相邻邻居。
与第4类表格相比,第3类表格的结果相对较差。这是因为类别4图像也包含来自类别的1和2以研究透视失真对简单图像的影响。我们得出结论,尽管图形网络在合并行和列方面存在困难,但它们优雅地处理了透视失真。
VI 结论与未来工作
在这项工作中,我们使用图模型重新定义了结构分析问题。我们在表格识别问题上展示了我们的结果,并且我们也论证了几种其他文档分析问题如何可以使用这个模型来定义。卷积神经网络最适合于寻找代表图像特征,而图网络最适合于快速消息传递在顶点之间。我们已经表明我们可以将这两种能力结合起来使用聚集操作。到目前为止,我们只使用位置特征为顶点,但是对一个真实世界的数据集,自然语言处理特征如GloVe也可以使用。总之,图神经网络对于结构分析问题工作得很好,我们期待在未来几年内看到更多关于这方面研究的进展。

